Advertisement
Reinforcement learning can seem abstract, but it’s really about helping machines make better decisions over time. One algorithm that's gained steady popularity in this space is Proximal Policy Optimization or PPO. It's designed to improve how machines learn through interaction, aiming for balance: fast enough to learn useful behaviours but stable enough not to break during training.
PPO has become a favourite in both research and applied machine learning because it offers solid performance without the complexity of older algorithms. It's practical, adaptable, and easier to implement in real-world environments compared to earlier methods.
Reinforcement learning (RL) involves agents making decisions to maximize long-term rewards in an environment. Learning a good policy—essentially a strategy for choosing actions—is difficult when outcomes aren't immediate. Policy gradient methods try to improve this by gradually adjusting the agent's strategy based on how good its decisions turn out to be. However, older versions, like vanilla policy gradients, were often unstable. Trust Region Policy Optimization (TRPO) improved stability but was computationally heavy and hard to scale.
PPO was developed as a simpler alternative that still maintained reliability. It introduced a way to limit how much the policy can change during training, avoiding the erratic behaviour often seen in previous methods. PPO focuses on improving the agent's decisions without letting them veer too far off course at each step. This approach has made it one of the most widely used methods in modern reinforcement learning.
PPO improves learning stability through a clipped objective function. In basic terms, this function discourages updates that change the agent's policy too much in one go. It calculates a probability ratio between the new and old policies. If the new policy is too different, PPO reduces the impact of the update. This check helps prevent policy collapse, where the agent adopts extreme or unproductive behaviors.

The algorithm is designed to be sample-efficient. PPO reuses data by performing several training steps on the same batch rather than discarding it after a single update. This is helpful in environments where data collection is expensive or slow. It's also compatible with both continuous and discrete action spaces, allowing it to handle a wide range of tasks.
Another benefit is that PPO avoids complex calculations, such as second-order derivatives, which TRPO relied on. This makes it much easier to implement using libraries such as PyTorch or TensorFlow. It supports mini-batch learning and works well with actor-critic architectures, which separate the decision-making and evaluation parts of the model.
In essence, PPO updates its strategy in a measured way. It doesn’t make drastic moves, which helps maintain consistent learning and reliable performance.
PPO performs well in environments that involve continuous control, such as robotics simulations or game environments with complex dynamics. Its reliability makes it suitable for tasks where random spikes in behaviour could lead to failure. Because of its ability to generalize across a variety of conditions, it's been adopted in research, gaming, and industrial AI systems.
Its simplicity also allows for faster experimentation. Developers don’t need to spend excessive time tuning settings just to get the model to learn something useful. PPO handles many of the challenges in reinforcement learning with fewer moving parts compared to more technical methods like TRPO.
That said, PPO isn’t perfect. Its conservative updates can slow down exploration in environments with sparse rewards, where useful feedback is rare. In such situations, the algorithm might stick too closely to what it already knows, missing out on better strategies.
It also has a few hyperparameters that can affect performance, including the clipping threshold and the number of epochs. While it’s more forgiving than some older methods, tuning still matters. Poor choices can reduce efficiency or cause training to plateau.
Still, for many applications, PPO offers a strong balance. It’s not the most aggressive learner, but it tends to be consistent, which often matters more in real-world tasks.anorher
You'll find PPO in use across a wide range of environments, from game-playing agents in OpenAI Gym to robotic simulations in Unity ML-Agents. Its general reliability and relatively low setup cost make it appealing to both new learners and experienced developers. Since it works with actor-critic frameworks and supports both discrete and continuous actions, it's flexible enough for many types of problems.

As a reinforcement learning algorithm, PPO has become the default choice in many settings. It doesn't demand exotic architectures or special hardware and can produce solid results across different domains. In many cases, PPO is the first method tried on a new problem, not because it’s always the best, but because it usually works well enough to set a benchmark.
However, there are times when other methods, such as Soft Actor-Critic (SAC) or Deep Deterministic Policy Gradient (DDPG), outperform PPO—especially in environments that require aggressive exploration or where continuous action control is more refined. But unless the task is especially tricky, PPO holds up well and is easier to debug and iterate on.
Its wide adoption means there’s strong community support and lots of documentation, which is especially helpful for developers and researchers who want to test new ideas without building everything from scratch.
Proximal Policy Optimization succeeds because it keeps things steady. It’s neither the flashiest nor the fastest, but it avoids the pitfalls of earlier methods while delivering dependable performance. With its clipped updates and data reuse, PPO focuses on small but consistent improvements. This makes it a useful and practical reinforcement learning algorithm for many types of tasks. It’s not without its challenges—particularly when exploration is key—but its strengths make it a top choice in both research and applied AI. For developers looking for an effective balance between ease of use and strong results, PPO is a smart tool to start with and continue building on as the field evolves.
Advertisement

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency
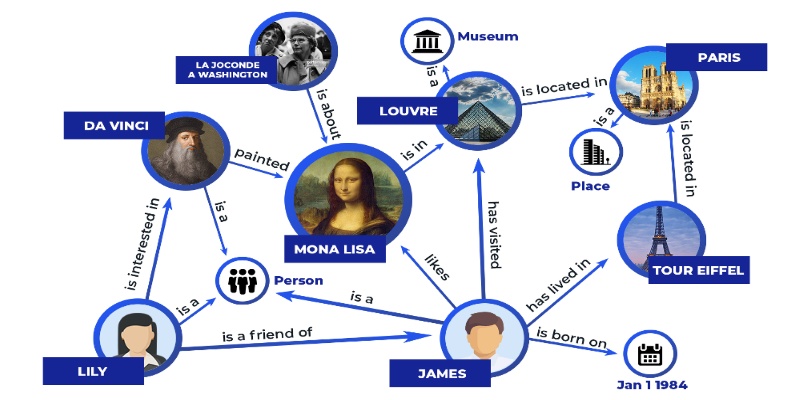
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed
How Summer at Hugging Face brings new contributors, open-source collaboration, and creative model development to life while energizing the AI community worldwide

Improve automatic speech recognition accuracy by boosting Wav2Vec2 with an n-gram language model using Transformers and pyctcdecode. Learn how shallow fusion enhances transcription quality

How are conversational chatbots in the Omniverse helping small businesses stay competitive? Learn how AI tools are shaping customer service, marketing, and operations without breaking the budget

Heard of Julia but unsure what it offers? Learn why this fast, readable language is gaining ground in data science—with real tools, clean syntax, and powerful performance for big tasks

How BERT, a state of the art NLP model developed by Google, changed language understanding by using deep context and bidirectional learning to improve natural language tasks

The White House has introduced new guidelines to regulate chip licensing and AI systems, aiming to balance innovation with security and transparency in these critical technologies

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring