Advertisement
You might already know Redis as the ultra-fast, in-memory data store often used for caching. But Redis has quietly been stepping beyond its typical role, and that's where Redis OM comes into the picture. Redis OM (Object Mapping) lets you treat Redis like a proper database, not just a cache layer you forget to clear. And when you mix that with Python, things start to get quite interesting.
Gone are the days when working with Redis meant manually juggling hashes and string keys. Redis OM for Python brings a more natural, model-driven way to store, retrieve, and query your data. It doesn't try to mimic SQL. Instead, it leans into what Redis is already good at and wraps it all in a Pythonic interface that feels intuitive right away. If you like building apps that are both fast and clean to maintain, this isn't something you want to skip.
At the heart of Redis OM is the idea of turning data into Python objects that behave like real-world entities. Instead of raw dictionaries or serialized blobs, you define models using classes. Each model acts like a contract: what fields your data will have, what types they should be, and how you’ll interact with them.

Unlike traditional NoSQL databases that give you total freedom (sometimes to your detriment), Redis OM adds structure without the overhead of full-blown schemas. You still get flexibility, but with a predictable shape that cuts down on debugging and speeds up collaboration.
This is where things get fun. Redis OM automatically creates secondary indexes for you, which means you can actually run efficient queries on your data. Want to fetch all users who signed up last week or products below a certain price? That’s built-in—no fancy query builder needed.
The setup is almost comically simple. Install the package, connect to your Redis instance, and you’re ready. No waiting for database migrations, no configuration files the size of a novella. You’re building within minutes.
Let’s break down how you actually define and use models with Redis OM.
Before you do anything else, install the required packages:
pip install redis-om redis
This pulls in everything needed to connect and work with Redis using Redis OM.
You start by creating a connection to your Redis server. It can be local or hosted—doesn’t matter.
from redis_om import get_redis_connection
redis = get_redis_connection(
host="localhost",
port=6379,
decode_responses=True
)
Models inherit from redis_om.Model. Each attribute gets a type, which helps Redis OM figure out how to store and index the data.
from redis_om import Field, JsonModel
class Product(JsonModel):
name: str = Field(index=True)
price: float
in_stock: bool
Notice the Field(index=True) part? That tells Redis OM to make that field searchable.
Creating and saving an instance is as straightforward as using Python’s built-in types.
item = Product(name="Mechanical Keyboard", price=89.99, in_stock=True)
item.save()
That’s it. The item now lives in Redis.
If you've worked with raw Redis before, you know querying can feel like playing darts in the dark. Redis OM flips that on its head by offering a cleaner, more familiar interface.
Product.find(Product.name == "Mechanical Keyboard").all()
You’re not writing strings to build a query. You’re just using Python expressions, and Redis OM handles the rest. It uses its own underlying indexing to make this efficient, so you’re not paying the price of a full database scan.
Updating is done on the instance itself:
item.price = 79.99
item.save()
There’s no extra syntax for updating vs. inserting. Redis OM simply checks if the object already has an ID and updates accordingly.
item.delete()
One line, and it's gone. No need to chase down related keys or worry about cleanup. If your model includes embedded relationships, those can be handled too, without the tangled logic.
There are plenty of ORMs and data libraries out there. So why consider Redis OM?
Redis is already one of the fastest databases around. Redis OM doesn’t slow that down—it rides on top of it. Your queries are fast because the underlying structure is fast. It’s that simple.
This is especially helpful in applications that thrive on immediacy: analytics dashboards, real-time feeds, or eCommerce systems where price changes need to reflect instantly. Redis OM gives you object-level access while preserving that speed.
You don’t have to juggle between custom serializers and handcrafted Redis commands. Everything is abstracted in a way that still gives you control when you need it. The code stays readable, even when your models grow.
Redis isn’t just fast—it’s scalable. And Redis OM doesn’t put up roadblocks when your dataset grows. You can work with hundreds of thousands of objects without rewriting your codebase.
Redis OM in Python strikes a rare balance between simplicity and power. It takes everything developers appreciate about Redis—its speed, flexibility, and low overhead—and adds a clean, structured way to work with data. Instead of wrestling with raw commands or scattered keys, you get models that behave predictably and integrate smoothly into real-world applications. Whether you're building a real-time product feed, a live analytics dashboard, or just want faster data access without the usual boilerplate, Redis OM is worth a serious look. It doesn’t demand that you change your architecture. It simply fits in, makes things easier, and lets you move forward without slowing down.
Advertisement
Confused about where your data comes from? Discover how data lineage tracks every step of your data’s journey—from origin to dashboard—so teams can troubleshoot fast and build trust in every number

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring

Improve automatic speech recognition accuracy by boosting Wav2Vec2 with an n-gram language model using Transformers and pyctcdecode. Learn how shallow fusion enhances transcription quality
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk
How Summer at Hugging Face brings new contributors, open-source collaboration, and creative model development to life while energizing the AI community worldwide

Prepare for your Snowflake interview with key questions and expert answers covering Snowflake architecture, virtual warehouses, time travel, micro-partitions, concurrency, and more
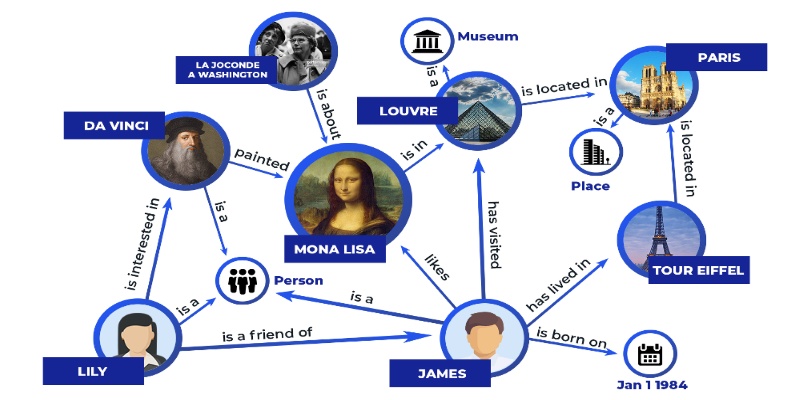
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery
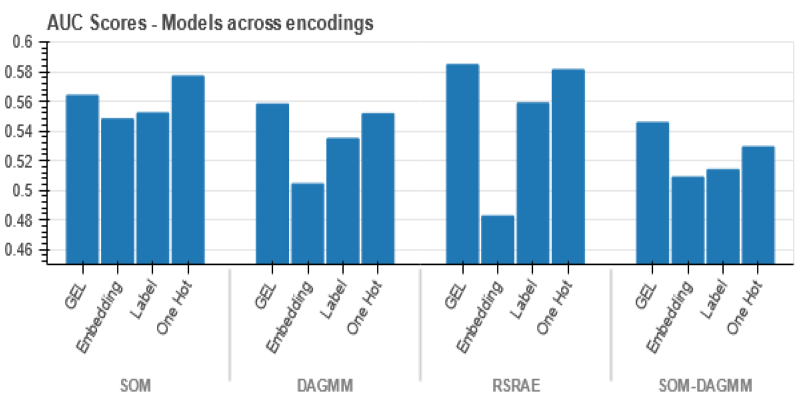
Wondering how Docker works or why it’s everywhere in devops? Learn how containers simplify app deployment—and how to get started in minutes

Struggling with a small dataset? Learn practical strategies like data augmentation, transfer learning, and model selection to build effective machine learning models even with limited data
Learn how to simplify machine learning integration using Google’s Mediapipe Tasks API. Discover its key features, supported tasks, and step-by-step guidance for building real-time ML applications

Learn how to create a Telegram bot using Python with this clear, step-by-step guide. From getting your token to writing commands and deploying your bot, it's all here