Advertisement
Speech recognition systems have become far more accurate over the past few years, largely thanks to models like Wav2Vec2. Built to learn directly from raw audio, Wav2Vec2 shifts away from handcrafted feature pipelines and delivers strong results, especially when fine-tuned on labelled datasets. However, no model is perfect out of the box.
There are still transcription errors—particularly when dealing with noisy inputs, rare words, or specialized language. One way to improve its accuracy without retraining the core model is by using n-gram language models during decoding. These models provide extra linguistic context, helping produce clearer and more coherent text output.
Wav2Vec2 works in two main stages. In the first, it learns to represent audio through self-supervised learning. It takes raw waveform input and masks parts of the audio, then predicts the masked portions based on context. This helps it build useful internal representations without needing any text labels at this stage. In the second phase, it’s fine-tuned with audio paired with transcripts to train it for speech recognition.
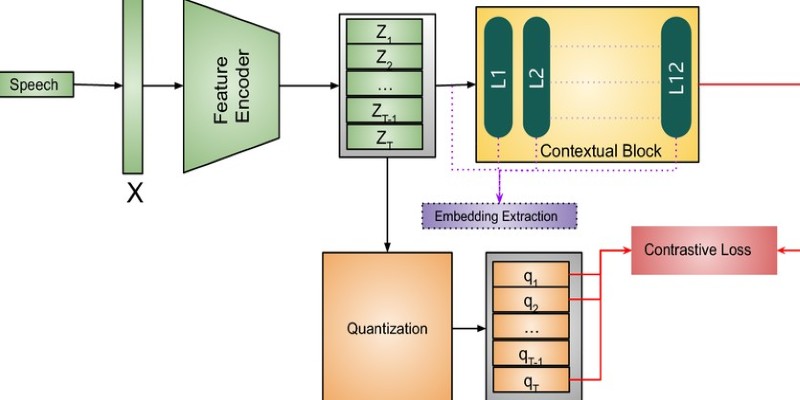
When it's time to generate text, the model outputs a series of logits that reflect the likelihood of various tokens (like characters or subwords) at each step. A decoding strategy is then used to turn these logits into actual text. Greedy decoding picks the most likely token at every time step. Beam search goes a step further, evaluating multiple possible token sequences to find the best fit.
However, neither method takes sentence-level coherence into account. A sentence might have the right individual sounds but still be awkward, misleading, or grammatically odd. That’s a limitation of relying on acoustic probabilities alone. It’s here that external language models—especially n-gram models—can offer a significant boost.
N-grams are sequences of n words used to predict the next word based on prior context. For example, a 3-gram (or trigram) looks at two previous words to predict the third. This method has been used in language modelling for years and remains relevant because of its simplicity, speed, and reliability.
In speech recognition, n-gram models act as a filter. When the acoustic model suggests multiple likely token sequences, the language model scores each based on how natural the sentence is. This allows the system to favour phrases that are more common or contextually appropriate, even if their acoustic probabilities are slightly lower.
This helps avoid transcription mistakes that stem from homophones, noise interference, or domain-specific terms. For instance, in a medical transcription task, a trigram model trained on medical text can guide the decoder toward choosing terms that are likely in that setting, like “blood pressure reading,” rather than similarly sounding phrases from everyday language.
Another benefit of using n-grams is their speed and low resource demand. Unlike large neural language models, they require very little memory and can run efficiently on smaller devices. That makes them practical for edge applications or environments with limited computing power.
The Hugging Face Hugging Face Transformers library provides the core tools for working with Wav2Vec2. But to use n-gram decoding, you need a couple of extra pieces: a trained n-gram model and a beam search decoder that can combine it with the acoustic outputs.
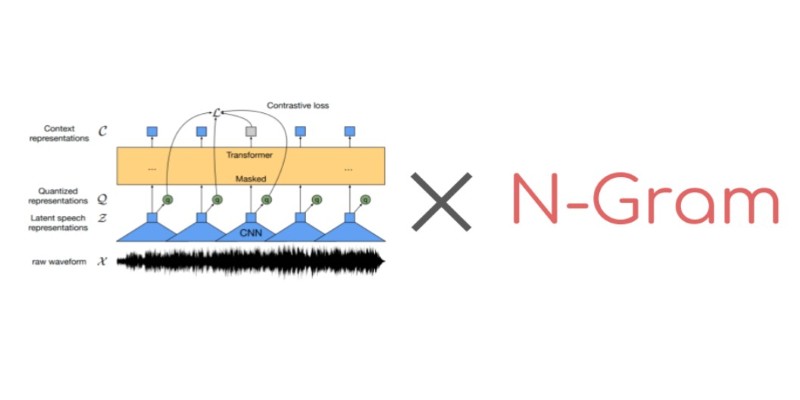
A typical setup involves using kenlm to train a statistical language model and pyctcdecode to manage beam decoding with language model fusion. kenlm builds the n-gram model from text data. It outputs a .arpa or binary format file that stores the probability of word sequences. pyctcdecode then integrates that model with Wav2Vec2's output to perform the decoding.
Here’s a simplified breakdown of the process:
Below is a minimal code example of integrating all components:
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from pyctcdecode import build_ctcdecoder
import torch
# Load pretrained Wav2Vec2 model
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
# Build KenLM decoder
vocab = list(processor.tokenizer.get_vocab().keys())
decoder = build_ctcdecoder(vocab, kenlm_model_path="lm.arpa")
# Process input audio
inputs = processor(audio, return_tensors="pt", sampling_rate=16000).input_values
with torch.no_grad():
logits = model(inputs).logits[0].cpu().numpy()
# Decode with n-gram model
transcription = decoder.decode(logits)
The decoding step is fast, and you can experiment with different n-gram models for different domains. For example, switching to a trigram model trained on legal documents can help transcribe court recordings more accurately.
In practice, the impact of adding an n-gram model depends on your data and environment. For open-domain, clean datasets like LibriSpeech, improvements might be minor. But in cases with noisy inputs, regional accents, or industry-specific vocabulary, the benefits become clearer.
N-gram models especially help when working with smaller labelled datasets. Since they don't require labelled audio, you can train a language model on any text corpus, large or small. That makes them a good fit for low-resource languages, technical fields, or transcription tasks involving jargon.
They also offer a level of interpretability. You can analyze why a particular sequence was favoured by examining its language model score. This can be useful in applications where transparency matters, such as medical documentation or legal records.
Another reason to consider n-gram fusion is that it’s non-invasive. It doesn’t alter the Wav2Vec2 model or require retraining. You just swap in a different decoding strategy. This makes it easy to try, compare, and adjust based on your needs.
Wav2Vec2 offers strong speech recognition, but its output can improve with n-gram language models. By guiding the decoding process with structured language patterns, n-grams help produce clearer, more accurate transcriptions—especially in specialized or noisy settings. Tools like kenlm and pyctcdecode make integration straightforward. This lightweight enhancement doesn’t require model retraining, making it a simple yet effective way to boost transcription quality across a wide range of applications.
Advertisement
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed

How TAPEX uses synthetic data for efficient table pre-training without relying on real-world datasets. Learn how this model reshapes how AI understands structured data

Learn how to create a Telegram bot using Python with this clear, step-by-step guide. From getting your token to writing commands and deploying your bot, it's all here
Learn how to simplify machine learning integration using Google’s Mediapipe Tasks API. Discover its key features, supported tasks, and step-by-step guidance for building real-time ML applications

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk

How accelerated inference using Optimum and Transformers pipelines can significantly improve model speed and efficiency across AI tasks. Learn how to streamline deployment with real-world gains
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery

How to train large-scale language models using Megatron-LM with step-by-step guidance on setup, data preparation, and distributed training. Ideal for developers and researchers working on scalable NLP systems

Struggling with a small dataset? Learn practical strategies like data augmentation, transfer learning, and model selection to build effective machine learning models even with limited data

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025