Advertisement
Sentence transformers are widely used in natural language processing for tasks like semantic search, sentence similarity, and question answering. Unlike word embeddings, they generate dense vector representations for entire sentences, making them more effective at capturing meaning. While pre-trained models often perform well out of the box, they may fall short on domain-specific tasks.
Fine-tuning these models helps tailor their understanding to particular contexts, improving performance and accuracy. Whether you're working with legal texts, customer service queries, or specialized content, training a sentence transformer can bridge the gap between general language understanding and practical application.
Sentence transformers adapt transformer-based models such as BERT or RoBERTa for sentence-level tasks. They work by applying a pooling operation over token embeddings to produce a fixed-size vector for the entire sentence. These embeddings can then be used for comparison, clustering, or fed into downstream models.
Most users don’t train sentence transformers from scratch. Starting from a pre-trained model is more efficient unless your data comes from a highly specialized or low-resource language. Fine-tuning allows the model to better understand the language style and terminology specific to your data. This process aligns the model with your task goals, such as identifying paraphrases, ranking search results, or grouping similar questions.
Fine-tuning is particularly useful when pre-trained embeddings are not delivering strong performance on your task. For instance, customer support systems benefit from a model that understands various ways users might phrase the same issue. Training adjusts the internal representation to reflect those variations more closely.
There are two primary approaches: supervised and contrastive training. Supervised learning uses labelled sentence pairs that indicate similarity or relevance. Contrastive training utilises pairs or triplets without explicit similarity scores, relying on learning by comparison. While supervised training usually produces stronger results, contrastive methods can be effective with large volumes of unlabeled data.
Fine-tuning begins with curating the right dataset. For supervised learning, sentence pairs must be labelled—either with similarity scores (on a scale from 0 to 1) or binary classes (similar or not). These pairs help the model understand how closely related two sentences are. For example, in a helpdesk setting, you might pair "How do I reset my password?" with "I forgot my login info" and assign a high similarity score.
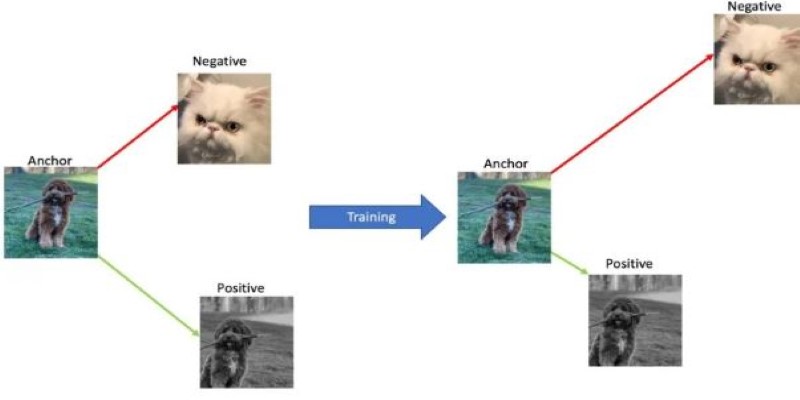
Contrastive methods, like triplet loss, require an anchor sentence, a positive match, and a negative example. The model learns to bring the anchor and positive closer together in embedding space and push the negative away. Another technique is using in-batch negatives with contrastive loss, where other examples in the batch serve as negatives, simplifying data preparation.
Dataset size influences performance. A few thousand examples might be enough for basic tasks, but complex domains benefit from tens of thousands. If your labelled data is limited, consider semi-supervised methods or data augmentation strategies.
Your choice of training objective depends on the task. Popular options include CosineSimilarityLoss, which works well with similarity scoring tasks, and MultipleNegativesRankingLoss, often used for information retrieval. Each loss function shapes the embeddings differently, so aligning it with your task is key.
The sentence-transformers library simplifies training and fine-tuning. It integrates with PyTorch and Hugging Face Transformers, offering tools to manage datasets, define losses, and train models with minimal setup.
To begin, load a pre-trained model, such as all-MiniLM-L6-v2 or paraphrase-MPNet-base-v2. These models balance speed and accuracy well and serve as reliable starting points.
Prepare training data using the InputExample format, which stores sentence pairs and their similarity label. You then feed this into a DataLoader for batching. Here’s a basic setup using cosine similarity loss:
from sentence_transformers import SentenceTransformer, InputExample, losses
from torch.utils.data import DataLoader
model = SentenceTransformer('all-MiniLM-L6-v2')
train_examples = [InputExample(texts=['Sentence A', 'Sentence B'], label=0.8)]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
train_loss = losses.CosineSimilarityLoss(model)
model.fit(train_objectives=[(train_dataloader, train_loss)],
epochs=3,
warmup_steps=100)
You can evaluate during training using metrics like Spearman correlation or accuracy on a validation set. This helps track whether the model is genuinely improving or overfitting.
Once training is complete, use .save() to store your model. It can be reloaded for embedding generation or integrated into larger systems. Embedding generation is fast, and caching results improve runtime efficiency.
Fine-tuning is much faster with a GPU. If using a CPU, expect longer training times. For resource-constrained environments, use smaller models like MiniLM or DistilBERT to reduce load.
A fine-tuned sentence transformer is well-suited for production tasks. In semantic search, it improves the relevance of results by generating more meaningful embeddings. In chatbots or helpdesk systems, it helps identify and match user intent more accurately, even when input phrasing varies.
You can deploy your model via an API using tools like FastAPI or Flask. The model can be hosted as a microservice or integrated into existing systems. Precompute embeddings for static content to save processing time.
Keeping the model updated is important. Language in user data changes over time, so periodic retraining on recent samples helps maintain accuracy. This is especially true in fast-moving domains like e-commerce, customer service, or tech support.
Bias in pre-trained models can persist after fine-tuning. Before deploying in sensitive applications, evaluate your model on fairness and potential edge cases. Adding diverse examples during training can help reduce unwanted behaviour.
Fine-tuning sentence transformer models is a practical way to improve performance on specific NLP tasks. It builds on strong base models, aligning them with your domain or application. Whether you're creating a better search engine, smarter chatbot, or more accurate classifier, fine-tuning helps make sentence embeddings more relevant and effective. With the right dataset, training strategy, and deployment setup, you can get solid results without starting from scratch.
Advertisement
How Summer at Hugging Face brings new contributors, open-source collaboration, and creative model development to life while energizing the AI community worldwide

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025
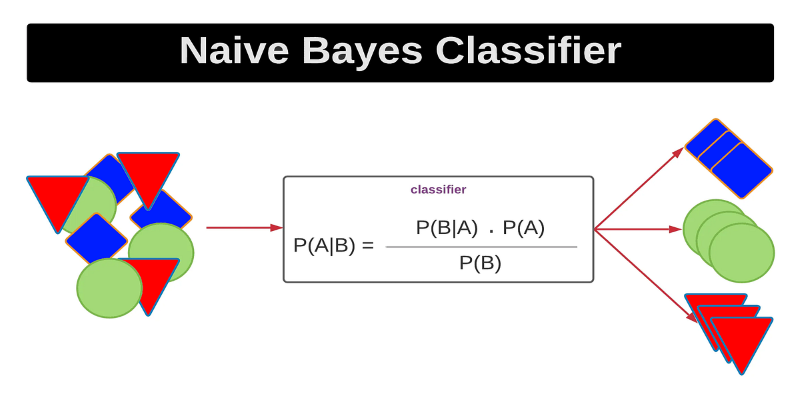
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines
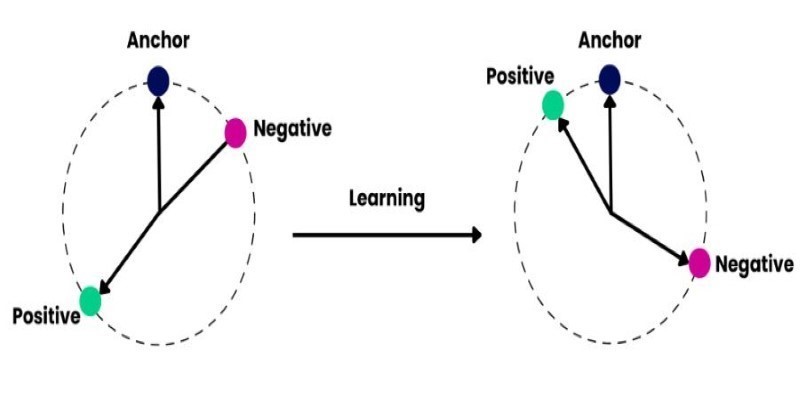
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

How accelerated inference using Optimum and Transformers pipelines can significantly improve model speed and efficiency across AI tasks. Learn how to streamline deployment with real-world gains

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming
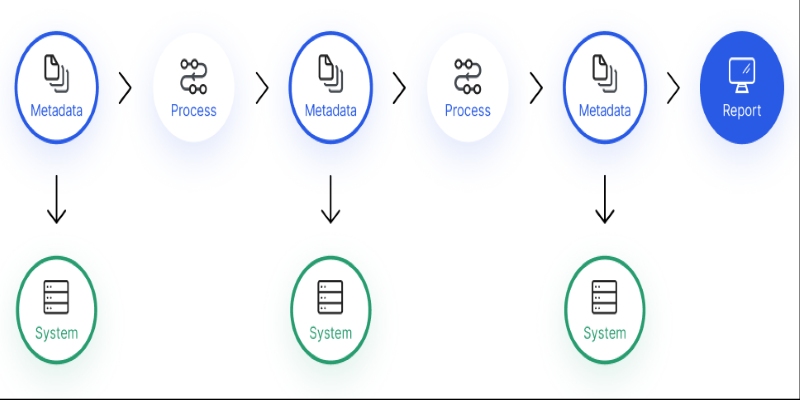
Confused about where your data comes from? Discover how data lineage tracks every step of your data’s journey—from origin to dashboard—so teams can troubleshoot fast and build trust in every number

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring