Advertisement
Artificial intelligence models continue to grow in size and capability, but this growth brings challenges when it comes to using them efficiently. Once a model is trained, the real goal is to make predictions quickly and affordably—what's known as inference. For Transformer-based models, which handle tasks such as text generation and question answering, speed is crucial.
Without optimization, these models can be too slow or costly to deploy at scale. Tools like Hugging Face's Optimum and Transformers pipelines offer a practical way to speed up inference without requiring developers to rewrite their code or change their workflows.
Inference is the stage where a trained model is used to make predictions on new input. It's different from training, which is done once or periodically. In production systems, inference happens all the time—responding to users, classifying content, and translating text. This needs to happen quickly. Large models with millions or billions of parameters can take too long to generate responses or cost too much to run, especially when used at scale.
Accelerating inference means reducing the time it takes for a model to return results. It also involves using less memory or compute power per request, which lowers operational costs. Various techniques support this goal: mixed-precision execution, graph optimization, model quantization, and hardware-specific compilation. These methods can be complex to implement manually. That’s where Optimum steps in, offering access to these tools through a consistent, high-level interface that integrates with Transformers.
Speed matters not just for responsiveness but for practical use. If a translation model takes several seconds to respond, users won’t wait. In batch processing, slow models can delay entire workflows. In both cases, optimization directly affects usability and cost.
Hugging Face’s Transformers library makes it easy to use pre-trained models for a wide range of tasks. Its pipelines feature provides a straightforward way to apply these models without building everything from scratch. You can load a model, run predictions, and handle tokenization with minimal setup.

The problem is that pipelines are built for ease of use, not performance. When performance becomes a priority, you’ll need more than the default setup. Optimum extends the capabilities of Transformers by integrating with optimized backends such as ONNX Runtime, OpenVINO, TensorRT, and others. These backends support model execution that’s faster and more efficient than standard PyTorch or TensorFlow.
Optimum handles the process of exporting and converting models so they can be used with these backends. Once a model is exported, it can be loaded into a Transformers pipeline in much the same way as before. The user experience stays simple, but the performance is significantly improved.
ONNX Runtime allows models to run as static graphs rather than dynamically executed code, which reduces overhead. OpenVINO targets Intel hardware and optimizes for CPU inference. TensorRT focuses on NVIDIA GPUs. Each backend has its strengths, and Optimum makes it easier to switch between them depending on your deployment setup.
To make the most of these tools, you typically begin with a pre-trained model in PyTorch. Let’s say you're using DistilBERT for sentiment analysis. You can fine-tune this model as usual. Once you're happy with its performance, you use Optimum to export the model into a format like ONNX, which is more efficient for inference.
Optimum provides tools to handle export and quantization. Quantization reduces model size by lowering precision—for example, from 32-bit floating point to 8-bit integers—while maintaining reasonable accuracy. After exporting and optimizing the model, you can load it using the same Transformers pipeline structure but with the optimized backend.
This workflow is relatively simple and doesn’t require learning new APIs. You don’t need to write device-specific code or manage memory layouts. The heavy lifting is handled by the combination of Transformers and Optimum libraries. This makes it easier to build and maintain applications, especially when working in a team or scaling across different environments.
The ability to switch backends depending on hardware also adds flexibility. If you're testing locally with the CPU, you can use OpenVINO. When moving to production on GPUs, you can switch to TensorRT. The same model, once optimized, can be used in multiple settings without rewriting core logic.
Acceleration has a real impact across a range of applications. For instance, in customer service automation, classification and summarization models are used constantly to analyze user input. In these cases, latency adds up quickly. A 200ms improvement in model response time, multiplied across thousands of daily interactions, leads to significant time and cost savings.

In mobile or edge computing environments, resource constraints are tighter. Devices may have limited processing power or battery life. Running a large model in full precision might be impossible. With Optimum’s quantization tools and backend support, these models can be slimmed down and made more efficient. That allows advanced capabilities, like real-time transcription or translation, to run on devices that wouldn’t otherwise support them.
Streaming applications also benefit. When generating subtitles or analyzing live input, speed is essential. A delay of even one second can make a service feel unresponsive. By using Optimum and pipelines together, it’s possible to push inference performance closer to real-time.
Scalability is another benefit. Cloud platforms charge based on usage—more memory, more time, higher cost. Accelerated inference lets you do more with less. That might mean handling more users with the same server or reducing the number of GPU hours needed for a daily workload.
These use cases highlight the broad utility of acceleration. Whether you're building for the cloud, the browser, or embedded systems, Optimum helps bring large models into more environments without trade-offs in quality.
Optimizing AI models isn’t just a technical bonus—it’s necessary for practical deployment. Transformers are capable but often too slow or costly without tuning. Hugging Face’s Optimum and Transformers pipelines simplify this process, offering faster, more efficient inference without requiring major code changes. Whether running in the cloud or on a device, these tools help reduce lag, control costs, and keep development straightforward while maintaining high model performance.
Advertisement

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming

The Hugging Face Fellowship Program offers early-career developers paid opportunities, mentorship, and real project work to help them grow within the inclusive AI community

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications

The White House has introduced new guidelines to regulate chip licensing and AI systems, aiming to balance innovation with security and transparency in these critical technologies

Heard of Julia but unsure what it offers? Learn why this fast, readable language is gaining ground in data science—with real tools, clean syntax, and powerful performance for big tasks
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

Struggling with a small dataset? Learn practical strategies like data augmentation, transfer learning, and model selection to build effective machine learning models even with limited data

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring
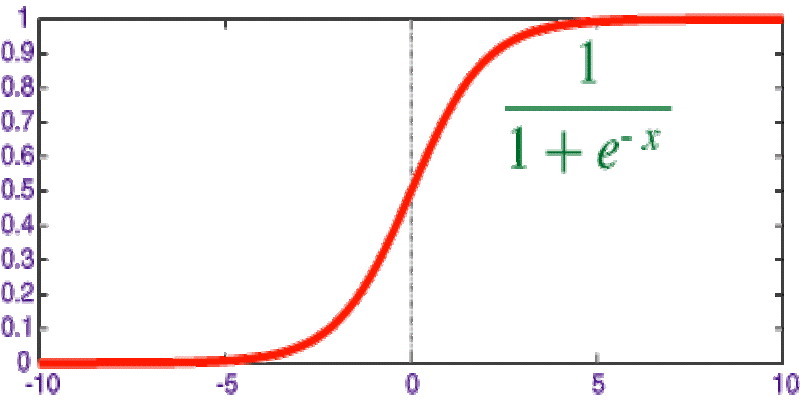
Explore the sigmoid function, how it works in neural networks, why its derivative matters, and its continued relevance in machine learning models, especially for binary classification