Advertisement
When someone talks about “where data comes from,” they’re talking about more than just a spreadsheet’s origin or who typed what into which cell. Data lineage is a full-blown map of how information flows—from the second it’s created to the moment it lands in a dashboard or report. Think of it like following footprints in fresh snow. Every step matters. It tells a story, and in this case, the story is about trust, accuracy, and clarity in data. Let’s break it down.
Data lineage refers to the tracing of data’s journey—from its starting point to its final use. It includes every transformation, formula, migration, and system the data passes through. For example, you might collect data from your website, run it through analytics software, store it in a data warehouse, and then use it to build reports. That entire path is your data lineage.
Think of it like tracking a package as it moves through each checkpoint—from warehouse to doorstep. Data lineage does the same for information, letting you see how it flows, changes, and ends up where it is.
But this isn’t just about satisfying curiosity. Understanding data lineage is critical to how organizations maintain control, trust, and accuracy in their data. Here's why it matters more than you might think:
If your monthly report looks off, you don’t need to guess where it went wrong. Data lineage lets you trace the issue directly to the source—whether it’s a broken script, missing field, or a bad transformation—so you can correct it quickly without wasting hours.
Many industries face strict rules about how data is collected, handled, and stored. With data lineage, you have a clear record of where the data came from and how it was used. This transparency makes audits and compliance checks much smoother.
When different teams rely on different tools or see different versions of the same data, confusion follows. Data lineage connects the dots, ensuring everyone is working from the same, verified source of truth.
Decision-makers need to trust the data they're using. When you can show exactly where the data came from and how it was processed, it builds confidence and leads to smarter, data-driven decisions.
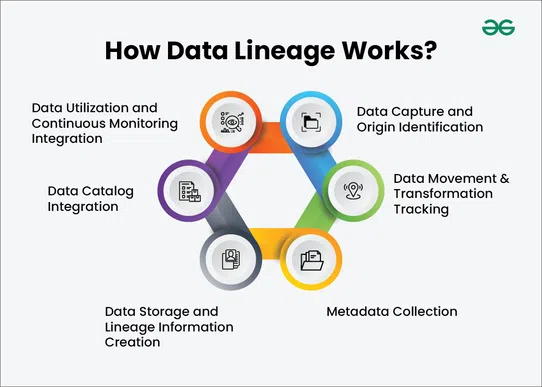
It’s easy to think of data lineage as one big map, but it has distinct parts. Knowing what you’re looking at helps when you need to trace a value or catch a mistake.
This is the starting point. It might be a manual data entry, a system log, a sales form—anything that creates raw data.
This is how the data travels from one place to another. APIs, ETL jobs, and scripts—these all fall under this step. If data is transferred across platforms, it leaves behind a trail.
Here, the raw data gets cleaned, combined, or reshaped. Maybe date formats have changed. Maybe two columns are merged. Whatever the action, it's logged as part of the lineage.
The data lands somewhere—maybe a cloud warehouse, maybe an internal database. Wherever it ends up, it’s part of the trail.
Finally, someone uses the data. It could show up in a dashboard, get used in a report, or be fed into a machine learning model. This final step completes the lineage.
While it’s possible to trace data manually (in theory), it’s rarely practical. Too many sources. Too many systems. That’s where tools step in to take the burden off your shoulders.
Designed for big organizations that need to stay consistent across teams. Collibra makes it easy to track lineage alongside data governance.
Known for its smart catalog features, Alation helps you see how data is connected and where it’s coming from. It also supports collaboration so teams can stay on the same page.
A long-time player in the data space, Informatica’s tools offer detailed mapping. If you're working with lots of different sources, this one keeps things in order.
An open-source option, especially useful if you’re dealing with the Hadoop ecosystem. It offers metadata management along with lineage.
For teams already deep in Microsoft’s ecosystem, Purview helps visualize lineage directly within Azure services.
Focused heavily on automation. Manta scans code, finds dependencies, and draws out the data flow without needing much manual input.
Setting up data lineage takes effort upfront, but once it’s in place, it saves time and headaches in the long run. Here’s how to get started in a structured way:
Don’t try to trace every byte of data from day one. Start with critical reports or high-risk data. Choose areas where mistakes are costly or visibility is poor.
List where the data originates and where it ends up. This might include databases, third-party apps, internal tools, and final dashboards.
This is the heart of it. What tools move your data? What transformations happen? Get detailed. Document scripts, APIs, ETL processes—everything that alters or moves data.
Manual tracking works for one-time checks, but for ongoing visibility, automation is key. Choose a tool that fits your tech stack and budget.
Systems change. So do workflows. Set a schedule to review your lineage map and make updates. Even small changes in logic or flow can throw things off if not tracked.
Data lineage isn’t just for technical folks or compliance teams. It’s for anyone who relies on data to make decisions. And that’s pretty much everyone. When you can trace how your data came to be, you avoid guessing, reduce errors, and spend less time cleaning up messes.
More importantly, you build something stronger—trust not just in the numbers, but in the process behind them. And that, in any business, makes a difference.
Advertisement

Struggling with a small dataset? Learn practical strategies like data augmentation, transfer learning, and model selection to build effective machine learning models even with limited data

The White House has introduced new guidelines to regulate chip licensing and AI systems, aiming to balance innovation with security and transparency in these critical technologies

Explore how ACID and BASE models shape database reliability, consistency, and scalability. Learn when to prioritize structure versus flexibility in your data systems

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025

Gradio is joining Hugging Face in a move that simplifies machine learning interfaces and model sharing. Discover how this partnership makes AI tools more accessible for developers, educators, and users

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk

Heard of Julia but unsure what it offers? Learn why this fast, readable language is gaining ground in data science—with real tools, clean syntax, and powerful performance for big tasks

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability

How BERT, a state of the art NLP model developed by Google, changed language understanding by using deep context and bidirectional learning to improve natural language tasks

How are conversational chatbots in the Omniverse helping small businesses stay competitive? Learn how AI tools are shaping customer service, marketing, and operations without breaking the budget

Are you running into frustrating bugs with PyTorch? Discover the common mistakes developers make and learn how to avoid them for smoother machine learning projects
Wondering how Docker works or why it’s everywhere in devops? Learn how containers simplify app deployment—and how to get started in minutes