Advertisement
Learning PyTorch can feel smooth at first. Its syntax is clean, and there’s plenty of documentation around. But once you move past the basic tutorials, it's easy to run into frustrating bugs that seem to pop up out of nowhere. Most of the time, these issues are not because PyTorch is broken, but because something was overlooked or misunderstood. That’s what this guide is about — flagging the mistakes that keep showing up and pointing out where things go wrong, so you don't have to figure it out the hard way.
One of the most common issues happens when tensors and models don’t share the same device. For example, your model might be on a GPU while the data stays on the CPU. At first glance, the error message might not make sense, but under the hood, PyTorch doesn’t allow operations between tensors living on different devices.
This usually happens when the model is moved to .cuda(), but the data isn't. You think everything's ready to go, and then PyTorch throws a mismatch error. It's not that your code structure is flawed — you just forgot to move a piece.
Always make sure both the model and the data are on the same device. A small helper function that sends everything to the same location can save time and reduce the risk of mismatches. Also, don't just call .cuda()—prefer to(device) with a device variable. That way, you're not hardcoding and can handle both GPU and CPU setups smoothly.
If you've used .backward() and then tried to use the output again, you might have seen PyTorch complain about "trying to backward through the graph a second time." This happens because the tensor still holds onto the computation graph. When PyTorch does backpropagation, it tracks all the operations you did. If you reuse the same tensor without detaching it, you're telling PyTorch to track it again, and it gets confused.
It gets worse in loops or during logging, where you might be saving outputs for visualization or analysis. Without calling .detach() or .item(), you're also holding onto the entire graph, which uses memory unnecessarily.
Use .detach() when you don’t need gradients anymore, especially before storing predictions or loss values. If you only need the number, use .item() to convert a tensor with one element into a regular Python number. That cuts the link and keeps memory usage in check.
You train the model, get decent results, and then during validation or inference, the numbers start looking off. BatchNorm and Dropout are likely the culprits. These layers behave differently during training and evaluation. If the model is still in training mode during testing, Dropout will randomly zero out some units, and BatchNorm will use the running statistics incorrectly.
It's an easy fix, but one that's often missed, especially when testing quickly or saving checkpoints.
Before evaluating the model, always call model.eval(). And when switching back to training, use model.train() again. These small switches control important behavior that can completely change results without you realizing it.
PyTorch allows in-place operations — like x += 1 or x.relu_() — which modify the data directly. They’re efficient in terms of memory, but they can also mess up gradient tracking. In-place operations don’t always play nice with autograd, especially when they overwrite values that are still needed for computing gradients.
Errors that result from this are hard to trace because the code looks fine on the surface. But once you dig deeper, it turns out the operation wiped out values that PyTorch was still planning to use.
Use in-place operations only when you're sure the tensor won't be used again for gradient computation. If you're unsure, stick to the out-of-place versions like x = x.relu() instead of x.relu_(). They’re safer and reduce the risk of running into silent bugs.
Unlike some other frameworks, PyTorch doesn't automatically zero out gradients after every backward pass. If you forget to call the optimizer.zero_grad(), the gradients will keep accumulating. This changes the effective gradient and can cause the model to behave unpredictably. You might think your learning rate is too high or too low, but the real issue is that the gradients are doubling or tripling in the background.
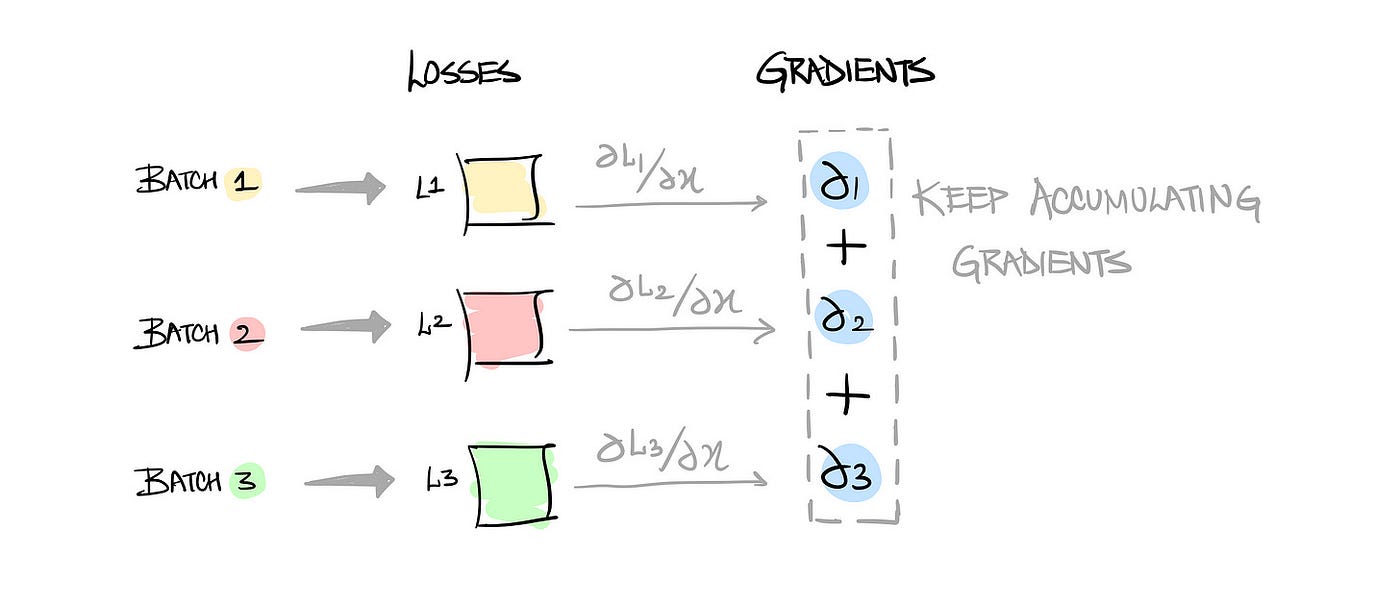
This mistake usually shows up when you’re doing custom training loops, especially during fine-tuning or when testing different schedules.
Make it a habit to call the optimizer.zero_grad() right before you call .backward(). It's not optional. Also, avoid placing it after .step(), because then it's already too late.
If you’re fine-tuning a pretrained model, chances are you want to keep some of the layers frozen. But just setting requires_grad=False is not enough. You also have to make sure your optimizer isn’t still updating those parameters.
Many times, people load a pretrained model, freeze some layers, and pass the entire model’s parameters to the optimizer. As a result, those "frozen" layers are still being updated because the optimizer doesn’t care about requires_grad.
Filter out parameters that shouldn’t be trained before passing them to the optimizer. A quick way to do this is:
python
CopyEdit
params = filter(lambda p: p.requires_grad, model.parameters())
optimizer = torch.optim.Adam(params, lr=1e-4)
This makes sure only the right parts of the model are being updated.
Most mistakes in PyTorch don't come from writing bad models — they come from missing small details. Whether it's something as basic as setting .eval() or as technical as avoiding in-place operations, these slips can make debugging unnecessarily hard. The good news is that once you know what to watch for, they're easy to avoid. So keep an eye on the device placements, handle gradients carefully, and don't assume that the framework will correct the small stuff for you. It won't. But once these habits are in place, working with PyTorch becomes a lot smoother.
Advertisement

Prepare for your Snowflake interview with key questions and expert answers covering Snowflake architecture, virtual warehouses, time travel, micro-partitions, concurrency, and more
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines

How are conversational chatbots in the Omniverse helping small businesses stay competitive? Learn how AI tools are shaping customer service, marketing, and operations without breaking the budget

How to train large-scale language models using Megatron-LM with step-by-step guidance on setup, data preparation, and distributed training. Ideal for developers and researchers working on scalable NLP systems

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk

Explore how ACID and BASE models shape database reliability, consistency, and scalability. Learn when to prioritize structure versus flexibility in your data systems
Confused about where your data comes from? Discover how data lineage tracks every step of your data’s journey—from origin to dashboard—so teams can troubleshoot fast and build trust in every number

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring