Advertisement
In data engineering, two models often sit at opposite ends of the reliability spectrum: ACID and BASE. While they aim to manage data consistency, their methods couldn’t be more different. One offers structure and rigidity; the other leans into flexibility and scale. If you’ve ever wondered how databases maintain their integrity (or strategically loosen it), it comes down to how they lean toward ACID or BASE principles.
Let’s unpack both models—not by putting them head-to-head like boxers in a ring—but by observing how they shape the databases that power our digital tools.
ACID stands for Atomicity, Consistency, Isolation, and Durability. It’s the DNA of traditional relational databases. If you’ve used PostgreSQL, MySQL, or SQL Server, then you’ve already worked with systems that follow these rules.
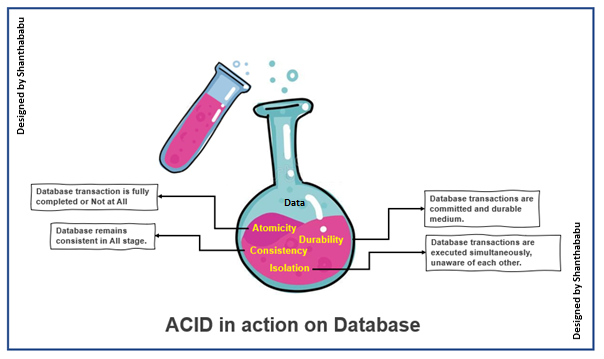
Imagine writing a transaction that updates two separate accounts: one gets debited, the other credited. With atomicity, either both updates succeed, or neither does. There's no in-between. This protects your data from ending up in a half-complete state.
Every time you write to the database, it must follow the predefined rules—called constraints. This ensures that you can’t insert invalid or incomplete data, like registering a user without a valid email if the schema requires one.
Transactions don’t interfere with each other, even when they run at the same time. So if two people are booking the last seat on a flight, the database handles it without double-booking.
Once a transaction is committed, it’s permanent—even in the face of system crashes. Data gets safely written to disk, not just memory. That’s why financial systems rely so heavily on ACID—they can't afford to lose a single entry.
ACID works well in systems where precision and integrity are non-negotiable. But what happens when speed, scale, and uptime start to matter more than perfect consistency?
BASE flips the script. It stands for Basically Available, Soft state, and Eventually Consistent. It's the mindset behind many NoSQL databases, such as Cassandra, Couchbase, and DynamoDB.
In BASE systems, the database prioritizes availability. That means it responds quickly, even during network hiccups or partial failures. The trade-off? The data you read might not be up to the second.
Data in a BASE system isn’t frozen in time. It can change, expire, or self-correct without requiring a firm transaction record for every adjustment. That fluidity makes these systems excellent for workloads where constant syncing is too expensive or unnecessary.
Rather than enforcing strict consistency after every transaction, BASE systems allow temporary mismatches. But they promise that, given enough time, all copies of the data will agree. Think of it as a guarantee that the truth will emerge—just not right away.
This model suits environments where high availability is more important than absolute real-time consistency. Social media platforms, messaging apps, and IoT systems frequently operate this way.
Rather than pitching one as better than the other, think of them as options suited for different types of problems. Each comes with its own strengths and trade-offs. The better question is how to understand their practical impact in modern data pipelines.
You’ll often find ACID in the heart of systems that require reliable, traceable changes. Here’s how to structure your architecture if ACID is non-negotiable:
Start with a platform like PostgreSQL or SQL Server. These are built to support ACID operations natively and come with powerful tools for schema enforcement and transaction management.
Leverage foreign keys, unique indexes, and check constraints. These aren't just formalities—they ensure that your data doesn’t slip into an invalid state.
Batch related changes into a single transaction. For example, if you're processing a payment, wrap account debits, credits, and invoice updates together. This keeps the system resilient to failures during intermediate steps.
Durability goes beyond transaction logs. Set up database replication and regular backups so that committed changes remain safe even during hardware failures.
ACID provides predictability, and when you’re dealing with financial records, inventory systems, or anything that can't afford ambiguity, that predictability becomes your safety net.
BASE systems are often chosen for their ability to handle vast volumes of traffic and unpredictable workloads. Here's how you approach that setup:
Start with something like Cassandra, DynamoDB, or Couchbase. These systems are designed for horizontal scaling and eventual consistency.
Forget about joining multiple tables. Instead, model your data to match the queries you expect. Redundancy is part of the design here—data gets copied across nodes and regions for speed.
Plan for situations where two reads might return slightly different versions of the same data. Build your application logic to either tolerate or reconcile these differences over time.
Track updates with timestamps or vector clocks so that your system knows which version of data is most recent. This helps during sync operations between replicas.
BASE works best when availability trumps accuracy. Think recommendation engines, user analytics, and content feeds—places where being a few milliseconds out of date isn’t a deal-breaker.
Both ACID and BASE play key roles in today’s data architectures. ACID gives you structure and safety—ideal for environments where data integrity comes first. BASE, on the other hand, gives you resilience and speed, which matters more in systems under constant load and change.
Rather than picking sides, most modern architectures blend the two. Use ACID where precision counts, and lean into BASE where scale and availability drive the experience. It’s not about choosing the “right” model—it’s about choosing the right model for each part of your system.
Advertisement

How are conversational chatbots in the Omniverse helping small businesses stay competitive? Learn how AI tools are shaping customer service, marketing, and operations without breaking the budget

How accelerated inference using Optimum and Transformers pipelines can significantly improve model speed and efficiency across AI tasks. Learn how to streamline deployment with real-world gains
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency

Gradio is joining Hugging Face in a move that simplifies machine learning interfaces and model sharing. Discover how this partnership makes AI tools more accessible for developers, educators, and users

Prepare for your Snowflake interview with key questions and expert answers covering Snowflake architecture, virtual warehouses, time travel, micro-partitions, concurrency, and more

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025

Learn how to create a Telegram bot using Python with this clear, step-by-step guide. From getting your token to writing commands and deploying your bot, it's all here
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines

Improve automatic speech recognition accuracy by boosting Wav2Vec2 with an n-gram language model using Transformers and pyctcdecode. Learn how shallow fusion enhances transcription quality