Advertisement
Training a large language model might sound out of reach, but with the right framework and some preparation, it's manageable—even outside big tech labs. Megatron-LM, developed by NVIDIA, is designed for training massive transformer models using distributed GPUs. It's built on PyTorch and supports model parallelism across GPUs, making it efficient for large-scale training.
Whether you're starting from scratch or fine-tuning an existing model, understanding how to use Megatron-LM properly helps you train models that can handle complex language tasks. This guide walks through setup, data preparation, configuration, and execution clearly and directly.
To get started, prepare a compatible system. Megatron-LM runs on multiple GPUs and is built on PyTorch, so install a supported version of PyTorch and NVIDIA's Apex for mixed-precision training. This setup is key for speed and memory efficiency. Clone the Megatron-LM repository from GitHub, create a virtual environment, and install dependencies like Ninja, mpi4py, and Sentencepiece. Apex must be compiled with the --cpp_ext --cuda_ext flags for full compatibility.
Megatron-LM isn't meant for single-GPU use. Even simple testing benefits from using at least 4 GPUs. For full-scale training—especially models over a billion parameters—you'll need dozens of GPUs, ideally connected with high-bandwidth networking like NVLink or Infiniband. Training large models also requires high VRAM (16GB+ per GPU) and efficient data pipelines.
Basic familiarity with distributed training concepts helps a lot here. Running jobs involves writing and adjusting shell scripts, passing arguments through the command line, and sometimes modifying configuration files. The environment must be stable because large model training often runs for days or weeks.
The model's performance depends heavily on the training data. Megatron-LM requires tokenized input in a binary format, so start by collecting clean text data. This could be public datasets, curated web content, or proprietary corpora. It should be diverse but relevant to the tasks the model will perform.
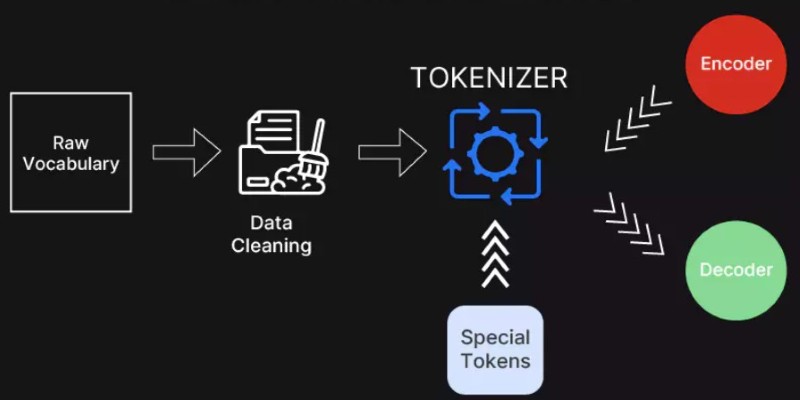
Use a tokenizer such as SentencePiece or GPT-2’s BPE-based tokenizer to convert the text into tokens. Megatron-LM includes scripts for tokenization and formatting. After tokenizing, convert the data into .bin and .idx files using the preprocess_data.py script. These files allow fast sequential access during training.
If you’re using several datasets, you can balance them using sampling weights. This is useful if one dataset is larger, but you don't want it to dominate the training. Clean, high-quality input helps the model learn structure, grammar, and semantics more effectively. Avoid excessive duplication or noise, which can degrade output quality.
Tokenizers must match the model's vocabulary size and type. You can reuse existing vocabulary or train a new one, depending on your goals. For domain-specific tasks, a specialized tokenizer may perform better than a general-purpose one.
With the data ready and the environment working, define the model architecture. Megatron-LM uses command-line arguments to set the number of layers, hidden units, attention heads, vocabulary size, and sequence length. For example, a GPT-style model with 24 layers, 1024 hidden units, and 16 attention heads would require corresponding flags passed at runtime.
Megatron-LM supports three types of parallelism: data, tensor, and pipeline. Tensor parallelism splits matrix operations across GPUs. Pipeline parallelism splits layers across GPUs. Data parallelism replicates models across nodes. These methods can be combined, allowing you to scale training across many GPUs efficiently.
Training is usually started via shell scripts, like pretrain_gpt.sh. These scripts set key parameters such as learning rate, optimizer (Adam or LAMB), weight decay, gradient clipping, batch size, and parallelism strategy. Megatron-LM also supports gradient accumulation and activation checkpointing to conserve memory.
The framework uses mixed-precision training (FP16) by default, improving speed and memory efficiency without loss in model accuracy. Loss values, learning rate, iteration times, and throughput are logged during the training process. You can set checkpoint intervals to resume training if it halts due to hardware or network issues.
Fine-tuning is handled similarly. You load a pre-trained checkpoint and train it further on a smaller, task-specific dataset. This is useful for adapting a general model to medical, legal, or technical writing, as well as for conversational agents. Fine-tuning typically uses lower learning rates and fewer steps than pretraining.
Training can take hours or days, depending on the model size, hardware, and data volume. Managing GPU utilization and choosing the right parallelism strategy can improve efficiency and reduce time. With proper configuration, Megatron-LM scales well from a few GPUs to hundreds.
Monitoring training involves more than watching loss numbers. Use Megatron-LM’s TensorBoard integration to visualize metrics such as training loss, validation loss, and learning rate over time. These plots help identify issues like vanishing gradients, overfitting, or unstable learning rates.
Validation is done using held-out data or task-specific benchmarks. Megatron-LM allows sampling outputs from the model mid-training. This gives a quick look at its language generation ability and coherence. You can also evaluate perplexity on clean datasets, which provides a numerical measure of language model quality.
Scaling up training introduces more complexity. For very large models (billions of parameters), balancing memory and computing becomes more important. Activation checkpointing saves memory by recalculating intermediate outputs, and gradient accumulation simulates large batch sizes without increasing memory use. These features are integrated into Megatron-LM and configurable via flags.
After training, save model checkpoints for later use. You can load them to continue training, fine-tune them on a different dataset, or export the model for deployment. Megatron-LM checkpoints include model state, optimizer state, and learning rate scheduler progress.
Deployment is outside Megatron-LM's scope, but exporting models for use with inference frameworks like ONNX or NVIDIA Triton is possible. The quality of output from a trained model depends on both data and training configuration. Testing across various prompts can help fine-tune the final output quality.
Training a language model with Megatron-LM involves setting up the environment, preparing data, configuring the model, and using efficient parallelism. It supports large-scale training with mixed precision and distributed computing, making it suitable for building high-performing transformer models. While it’s built for heavy-duty tasks, it’s flexible enough for various use cases. For those looking to train models that produce strong language output, Megatron-LM offers a dependable starting point.
Advertisement

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency

Gradio is joining Hugging Face in a move that simplifies machine learning interfaces and model sharing. Discover how this partnership makes AI tools more accessible for developers, educators, and users

Learn how to create a Telegram bot using Python with this clear, step-by-step guide. From getting your token to writing commands and deploying your bot, it's all here

How BERT, a state of the art NLP model developed by Google, changed language understanding by using deep context and bidirectional learning to improve natural language tasks

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications

AI is changing the poker game by mastering hidden information and strategy, offering business leaders valuable insights on decision-making, adaptability, and calculated risk

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features
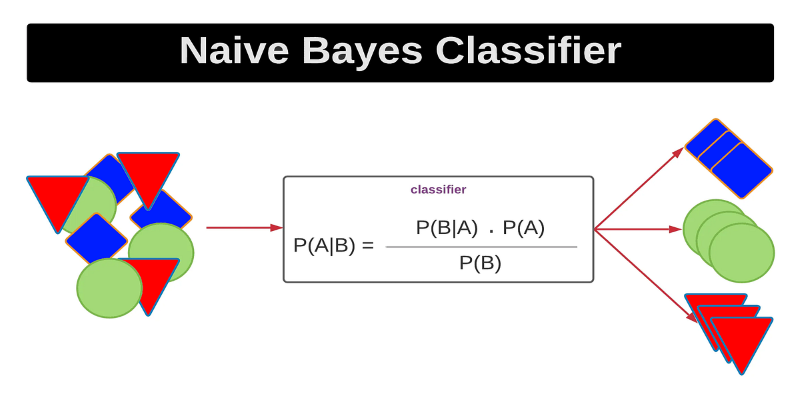
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines
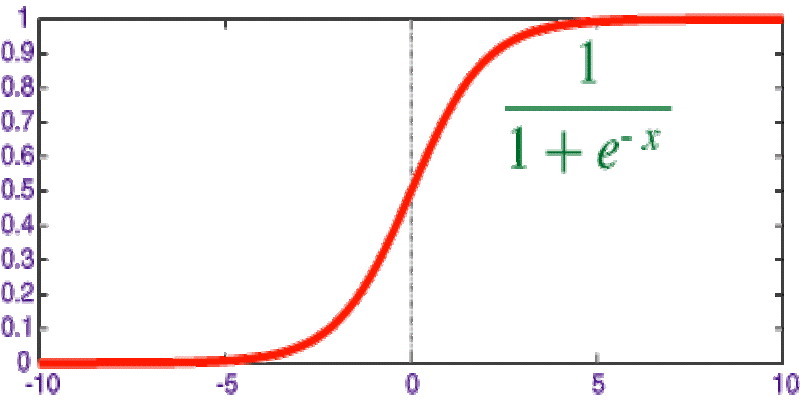
Explore the sigmoid function, how it works in neural networks, why its derivative matters, and its continued relevance in machine learning models, especially for binary classification

How TAPEX uses synthetic data for efficient table pre-training without relying on real-world datasets. Learn how this model reshapes how AI understands structured data