Advertisement
When working on a machine learning project, everything seems to fall into place—until you realize your dataset isn’t quite what you hoped it would be. Maybe it’s too small, maybe it’s not varied enough, or maybe it just doesn’t reflect the problem well. And no matter how good your model is, it won’t do much without quality data behind it. But here’s the thing: working with limited data doesn’t mean you're out of options. You just have to be a bit more thoughtful, a little more strategic, and yes, sometimes a bit creative.
Let’s explore what can actually be done when your dataset is smaller than ideal, and how to make the most out of every data point you have.
Before doing anything fancy, it helps to take a closer look at what you’re already working with. You’d be surprised how much can be done just by understanding the dataset inside-out. Ask yourself:

You can often squeeze a lot more value from the same dataset just by reshaping or rethinking it. For instance, a timestamp can be broken down into day of the week, time of day, or even whether it’s a holiday. These new angles might give your model just enough context to learn better patterns.
It also helps to look at class balance. If one category heavily outweighs the rest, your model might simply learn to guess that one every time. This doesn’t mean your model is “smart”—it means your data is leaning too hard in one direction. When that happens, the fix isn’t always collecting more data. Sometimes, it’s about rebalancing what you already have.
Data augmentation isn't just for images, though that's definitely where it shines. In computer vision, it's standard practice to flip, crop, rotate, or adjust brightness to get more from fewer images. But similar tricks exist for other data types, too.
Text: You can swap out words for synonyms, shuffle sentence structure slightly, or paraphrase entries. Tools like back-translation (translating text into another language and then back again) can also help create new variations.
Audio: Shifting pitch, adding background noise, or stretching the signal can generate more training examples that feel fresh to the model.
Tabular Data: While augmentation here is trickier, methods like SMOTE (Synthetic Minority Oversampling Technique) can be useful for balancing categories in classification problems.
The key isn’t to generate data blindly—it’s to keep the underlying meaning intact while giving the model more to learn from.
One of the biggest advantages of working in machine learning today is how many high-quality, pretrained models are freely available. These models have already been trained on large datasets and can be fine-tuned for your specific use case.
Let’s say you're working with text. Instead of training a language model from scratch, you can start with something like BERT or GPT-based architectures that already understand language patterns well. From there, you only need a small amount of domain-specific data to fine-tune them for your task.
In image-related tasks, models like ResNet or EfficientNet offer a similar shortcut. You don’t need to teach them what an “edge” or “shape” is—they’ve already learned that. You just train them to recognize what matters for your particular problem.
This technique—known as transfer learning—can often take a project from stuck to successful with just a handful of examples. It’s not cheating; it’s making use of the heavy lifting that’s already been done.
Some algorithms handle small datasets better than others. If you're dealing with limited data, switching your model might be just what you need.
Decision Trees and Random Forests: These are surprisingly good with smaller datasets. They’re also easy to interpret and quick to train.
Naive Bayes: Especially in text classification, Naive Bayes models punch well above their weight. They're simple, require fewer data points, and often deliver competitive results.
K-Nearest Neighbors (KNN): While not ideal for large datasets, KNN can work very well when data is limited and you’re focusing on similarity between examples.
Support Vector Machines (SVM): SVMs are known for doing well in smaller, high-dimensional datasets. They’re particularly effective when there’s a clear margin of separation between classes.
Also, keep in mind that deep learning, while powerful, typically needs a lot of data to shine. If you're working with a small dataset, going for the flashiest neural network might not be the best move, at least not without pretraining or augmentation.
When working with limited data, evaluating model performance reliably becomes even more critical. Techniques like cross-validation can help ensure your model isn’t just performing well by chance. K-fold cross-validation, in particular, partitions your small dataset into several subsets, training and validating multiple times on different combinations. This gives a more accurate and robust estimate of how your model will generalize.
Regularization techniques also come in handy. Methods such as L1 (Lasso) and L2 (Ridge) regularization penalize overly complex models, preventing overfitting when the dataset is sparse. By keeping models simpler and more disciplined, regularization can significantly enhance performance on limited data, ensuring the model learns genuinely useful patterns rather than memorizing specific examples.
Not every project comes with a perfect dataset, and that's okay. The reality is that a lot of machine learning work happens under real-world constraints. Whether you're working with a niche problem, a budget, or just starting out, limited data doesn't mean limited results.
With a sharp eye and the right techniques, you can turn even a modest dataset into something valuable. Start by making the most of what’s already there. Then, layer in smart augmentations, take advantage of transfer learning, and don’t hesitate to switch to models that are better suited for the data size you have. In the end, it’s not just about the quantity of data—it’s about how you use it.
Advertisement

Are you running into frustrating bugs with PyTorch? Discover the common mistakes developers make and learn how to avoid them for smoother machine learning projects

How TAPEX uses synthetic data for efficient table pre-training without relying on real-world datasets. Learn how this model reshapes how AI understands structured data

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming
Wondering how Docker works or why it’s everywhere in devops? Learn how containers simplify app deployment—and how to get started in minutes

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025
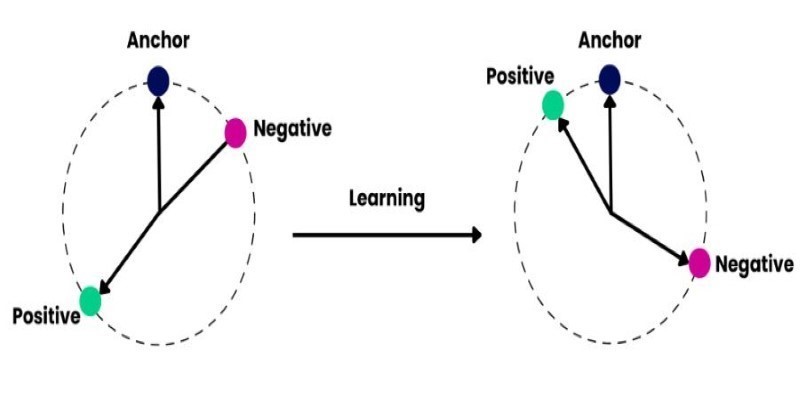
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

The White House has introduced new guidelines to regulate chip licensing and AI systems, aiming to balance innovation with security and transparency in these critical technologies

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features

Improve automatic speech recognition accuracy by boosting Wav2Vec2 with an n-gram language model using Transformers and pyctcdecode. Learn how shallow fusion enhances transcription quality