Advertisement
Writing organized Python code becomes more essential as your app moves beyond quick scripts and grows into something layered. Without a structure, things can quickly spiral. Query logic sneaks into business functions. Data is passed around as raw dictionaries. And changes? They turn into a hunt across multiple files. That’s why two design patterns — Data Access Object (DAO) and Data Transfer Object (DTO) — help bring some sanity into your project.
DAO keeps your interaction with the database in one place. DTO gives you a structured way to move data through your app. Used properly, they help separate responsibilities, reduce code duplication, and make everything easier to maintain.
The Data Access Object acts as the middle layer between your program and the database. Instead of spreading raw SQL throughout your codebase, you centralize it inside a DAO. That way, all create, read, update, and delete operations are in one class or module.
For instance, if your program manages contacts, your DAO would be the one sending and receiving data from the contacts table. Your app doesn’t need to know what the SQL looks like. It just makes a method call like contact_dao.get_all() or contact_dao.save(new_contact).
This doesn’t just improve readability. If you need to switch from SQLite to PostgreSQL, or update your schema, you won’t have to track down scattered queries. You update the DAO, and everything else keeps running.
Let’s take a look at a basic DAO for managing contacts:
python
CopyEdit
import sqlite3
from typing import List, Optional
from contact_dto import ContactDTO
class ContactDAO:
def __init__(self, db_path):
self.conn = sqlite3.connect(db_path)
def get_by_id(self, contact_id: int) -> Optional[ContactDTO]:
cursor = self.conn.cursor()
cursor.execute("SELECT id, name, email FROM contacts WHERE id = ?", (contact_id,))
row = cursor.fetchone()
return ContactDTO(*row) if row else None
def get_all(self) -> List[ContactDTO]:
cursor = self.conn.cursor()
cursor.execute("SELECT id, name, email FROM contacts")
rows = cursor.fetchall()
return [ContactDTO(*row) for row in rows]
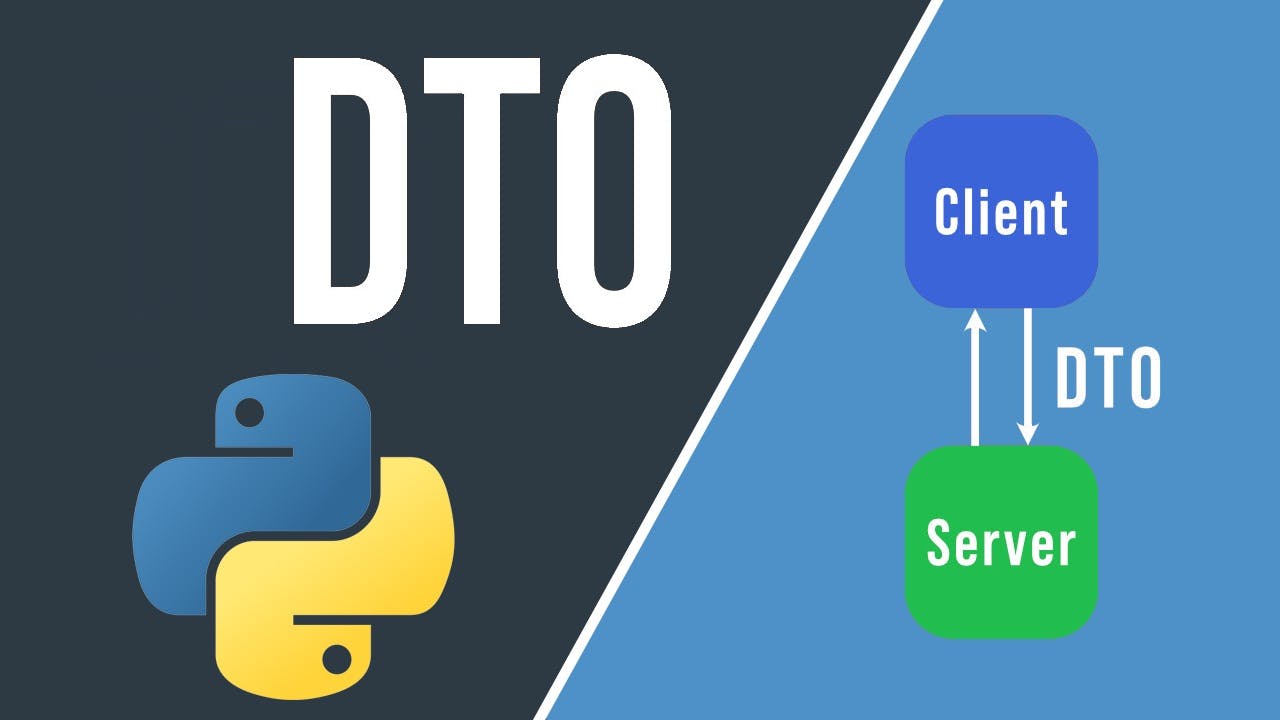
def save(self, contact: ContactDTO):
cursor = self.conn.cursor()
cursor.execute(
"INSERT INTO contacts (name, email) VALUES (?, ?)",
(contact.name, contact.email)
)
self.conn.commit()
By wrapping database operations in this class, you're creating a single source of truth for interacting with your data storage. That makes debugging easier and cuts down on accidental duplication.
The Data Transfer Object is much simpler in behavior — in fact, it doesn’t do much. And that’s by design. A DTO holds structured data. Nothing more. No logic. No dependencies. It’s just a container for data that needs to be passed between layers of your app.
This becomes useful when you’re handling more than a couple of fields. Instead of juggling a mix of dictionaries and lists with unclear keys, you use a DTO that clearly defines its structure.
Python makes defining DTOs easy with dataclass:
python
CopyEdit
from dataclasses import dataclass
@dataclass
class ContactDTO:
id: int
name: str
email: str
If some fields are optional, you can provide default values:
python
CopyEdit
@dataclass
class ContactDTO:
id: int = 0
name: str = ''
email: str = ''
This structured format helps keep your code consistent. Developers know exactly what to expect from a ContactDTO object, and tools like autocomplete become more helpful.
You also avoid the silent errors that come with loosely structured data — like typos in dictionary keys or missing fields.
In a well-structured program, the DAO pulls data from the database and hands it off in the form of a DTO. That DTO can then move freely through the rest of your app, whether you're sending it to a user interface, an API endpoint, or some internal logic.
Here’s a quick example to show the handoff:
python
CopyEdit
def print_contacts():
dao = ContactDAO("contacts.db")
contacts = dao.get_all()
for contact in contacts:
print(f"{contact.id}: {contact.name} - {contact.email}")
In this case, the application code never touches SQL or raw tuples. It deals with clean Python objects. That makes the code easier to test, easier to read, and less prone to errors.
If you're starting a new project or refactoring an old one, here's how you can use DAO and DTO properly from the beginning.
Start by defining the structure of the data you want to work with.
python
CopyEdit
from dataclasses import dataclass
@dataclass
class ContactDTO:
id: int
name: str
email: str
This will represent a single record in your contacts system. Whether you’re displaying a list or adding new entries, this object will carry your data.
Next, you build the class that manages reading from and writing to the database. Avoid adding any business logic here. Keep it focused on data handling only.
python
CopyEdit
import sqlite3
class ContactDAO:
def __init__(self, db_path):
self.conn = sqlite3.connect(db_path)
def save(self, contact: ContactDTO):
cursor = self.conn.cursor()
cursor.execute(
"INSERT INTO contacts (name, email) VALUES (?, ?)",
(contact.name, contact.email)
)
self.conn.commit()
The goal is to wrap each database operation in its method. That way, any part of your app that needs to access the data can do it through a clear and reusable function.
With both DAO and DTO in place, your app code becomes more readable and less error-prone.
python
CopyEdit
def main():
dao = ContactDAO("contacts.db")
new_contact = ContactDTO(name="Charlie", email="[email protected]")
dao.save(new_contact)
contacts = dao.get_all()
for contact in contacts:
print(contact)
The business logic here — creating a new contact, saving it, and printing it — stays clean. No SQL. No field-matching. Just plain method calls and structured data.
It's important that you resist the temptation to add utility methods or logic inside the DTO. This class should not make decisions or interact with the database. It just holds data. If you need logic around contact validation or formatting, handle that in a service layer or elsewhere in your codebase.
DAO and DTO are simple patterns that bring clear structure to a Python application. DAO manages the communication with your data source and provides a central place for all data operations. DTO offers a lightweight, consistent container for passing data through your application.
Used together, they help reduce duplication, improve testability, and make your project easier to understand and maintain, especially as it grows in complexity. Whether you're building a tiny tool or a larger application, these patterns are easy to adopt and pay off almost immediately in the form of cleaner, more reliable code.
Advertisement

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025

Explore how ACID and BASE models shape database reliability, consistency, and scalability. Learn when to prioritize structure versus flexibility in your data systems

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features

Are you running into frustrating bugs with PyTorch? Discover the common mistakes developers make and learn how to avoid them for smoother machine learning projects

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming
Learn how to simplify machine learning integration using Google’s Mediapipe Tasks API. Discover its key features, supported tasks, and step-by-step guidance for building real-time ML applications
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed

Gradio is joining Hugging Face in a move that simplifies machine learning interfaces and model sharing. Discover how this partnership makes AI tools more accessible for developers, educators, and users

How Sempre Health is accelerating its ML roadmap with the help of the Expert Acceleration Program, improving model deployment, patient outcomes, and internal efficiency

Improve automatic speech recognition accuracy by boosting Wav2Vec2 with an n-gram language model using Transformers and pyctcdecode. Learn how shallow fusion enhances transcription quality