Advertisement
If you’ve dipped your toes into machine learning, chances are you’ve already brushed against the sigmoid function. It's not loud or flashy. It's subtle—yet it plays a key role in turning complex models into ones that can learn, adapt, and generalize. The sigmoid function takes any real-valued number and squashes it neatly between 0 and 1. But there’s more going on under the hood. Let’s break it down—what it is, how it works, and why its derivative is so often mentioned alongside it.
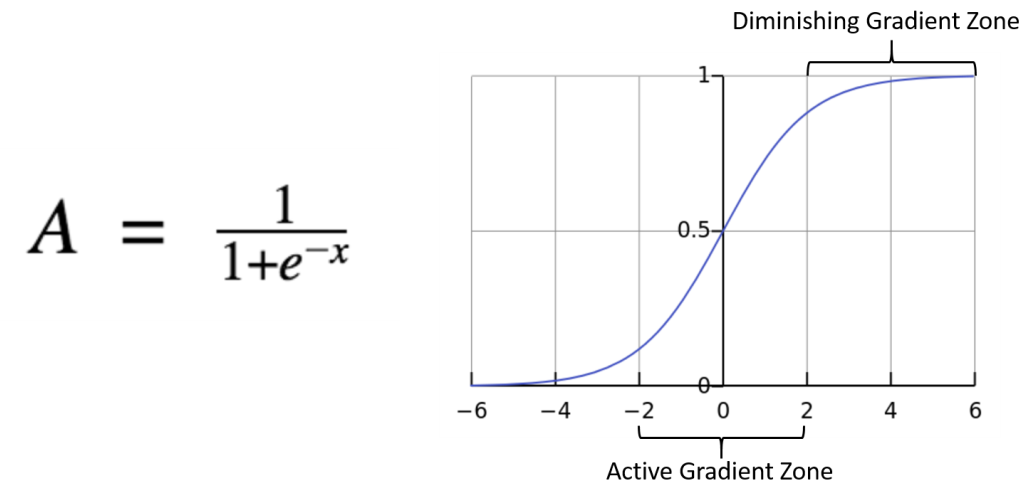
The sigmoid function is defined mathematically as:
σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
Takes any real number and compresses it neatly between 0 and 1, making it ideal for interpreting outputs as probabilities. This is particularly useful in logistic regression and binary classification tasks, where model outputs reflect confidence or likelihood.
When passed through the sigmoid function:
This creates its distinctive “S”-shaped curve.
If you’ve worked with training algorithms before, you’ll know that gradients—or derivatives—are everything. They tell us how to adjust our parameters to reduce the error. And luckily, the sigmoid function has a derivative that’s surprisingly tidy.
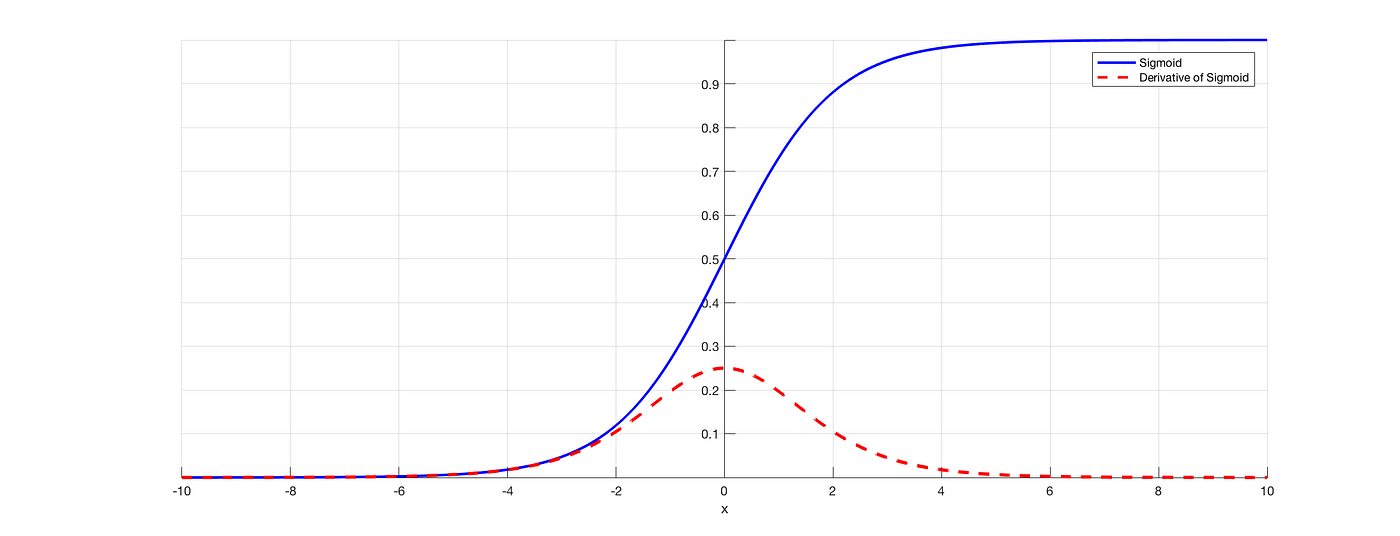
The derivative of σ(x) is:
σ(x) * (1 - σ(x))
Yes, that’s it. The derivative of the sigmoid function depends directly on the output of the function itself. That means once you've calculated the output, you already have what you need to find the derivative. No extra exponential calculations needed.
Let’s put that into context. Imagine you’re training a neural network, and one of your hidden units outputs a value of 0.8. The gradient at that point would be:
0.8 * (1 - 0.8) = 0.8 * 0.2 = 0.16
This tells us how sensitive the output is to changes in the input. In regions near 0 or 1, that product gets small, which is where things get tricky. Gradients close to zero can stall training, a phenomenon known as the vanishing gradient problem.
Still, the fact that the sigmoid derivative is bounded and relatively easy to compute makes it useful in simpler models where interpretability and ease of implementation matter more than raw speed.
Let’s walk through how the sigmoid function fits into a typical neural network, from input to output. We’ll use a basic example of binary classification.
Every neuron starts with a set of initial weights and a bias value. These are usually set randomly at the beginning of training. They determine how much influence each input will have.
When input values are fed into the network, each one gets multiplied by its corresponding weight. Then the bias is added. So the input to the sigmoid function looks like this:
z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b
This z is just a number, but it holds all the influence from the input layer.
Step 3: Apply the Sigmoid Function
Now, the output is calculated by plugging z into the sigmoid formula:
σ(z) = 1 / (1 + e^(-z))
This converts the weighted sum into a probability-like value, neatly bounded between 0 and 1.
The model's prediction is compared to the actual answer using a loss function, commonly binary cross-entropy when using sigmoid for classification. The goal is to reduce the difference between predicted and actual outcomes.
This is where the derivative comes in. During backpropagation, the derivative of the sigmoid function helps calculate how much each weight contributed to the error. Since we already know σ(z), we can quickly get:
σ(z) * (1 - σ(z))
This gradient then flows backward through the network, guiding how the weights should change.
Using the calculated gradients, the weights and biases are adjusted (typically using gradient descent or some variant). The idea is to shift them in a direction that reduces the overall error.
And then—repeat. Dozens, hundreds, or even thousands of times. That’s training in a nutshell.
While it’s true that newer activation functions like ReLU have largely taken over in deep learning architectures, the sigmoid function hasn’t been pushed aside completely. It still holds up well in models where interpretability is key. Logistic regression, for example, leans entirely on the sigmoid function. Why? Because its output can be read as a probability, which is exactly what’s needed in many real-world classification problems.
In shallow networks or binary classification setups, a sigmoid is often more than enough. It's straightforward, efficient, and easy to debug. When your goal is clarity over complexity, it's still a go-to option.
The sigmoid function might not be the flashiest tool in the machine learning toolkit, but it's one of the most practical. It's been around for decades, and despite the rise of deeper, more complex networks, it continues to earn its place, especially when clarity and simplicity are the priority. Its clean output, intuitive behavior, and easy-to-compute derivative make it a solid choice in many situations.
So the next time you're setting up a model and you see that familiar 1 / (1 + e^(-x)), know this: it’s not just a math formula. It’s a piece of machinery quietly doing its part to help your models learn and improve—one squashed number at a time. Stay tuned for more informative guides.
Advertisement

Are you running into frustrating bugs with PyTorch? Discover the common mistakes developers make and learn how to avoid them for smoother machine learning projects
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications

How accelerated inference using Optimum and Transformers pipelines can significantly improve model speed and efficiency across AI tasks. Learn how to streamline deployment with real-world gains

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability

Could one form field expose your entire database? Learn how SQL injection attacks work, what damage they cause, and how to stop them—before it’s too late

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features

Learn how to impute missing dates in time series datasets using Python and pandas. This guide covers reindexing, filling gaps, and ensuring continuous timelines for accurate analysis
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed

What does GM’s latest partnership with Nvidia mean for robotics and automation? Discover how Nvidia AI is helping GM push into self-driving cars and smart factories after GTC 2025
How to train and fine-tune sentence transformers to create high-performing NLP models tailored to your data. Understand the tools, methods, and strategies to make the most of sentence embedding models