Advertisement
The development of language models that understand structured data has grown quickly, but working with tables remains a challenge. Most models handle text well yet struggle when it comes to understanding how tabular data works. That’s where TAPEX comes in. Developed to pre-train on tables without needing real-world data, TAPEX changes the game.
It doesn't rely on manually collected tables or real databases. Instead, it uses synthetic data to train models that can read, interpret, and generate responses using table-based information. This approach not only saves time and cost but also opens doors for scalable training of table-centric models.
TAPEX stands for Table Pretraining via Execution, representing a significant shift in how machine learning models approach structured data. Traditional models need large datasets scraped from the web or collected from public sources, which can be noisy, inconsistent, or limited by access. TAPEX sidesteps that entirely. It uses synthetic question-table pairs generated through automatic processes. Rather than mimicking the data found in spreadsheets or databases, it focuses on logical structure and pattern learning.
The key idea behind TAPEX is to simulate how a human would reason over a table to find an answer. For instance, if someone asked, “What is the highest score in this column?” a model trained using TAPEX would not just match words—it would understand that it needs to locate the relevant column, identify numerical values, and return the highest one. That logical step-by-step reasoning mirrors how people use tables, and it’s what sets TAPEX apart.
The “liftoff” in its name isn’t just catchy; it reflects a major leap. TAPEX models, trained only on synthetic data, perform remarkably well when fine-tuned on real tasks like WikiSQL, SQA, and TabFact. It’s the equivalent of learning how to fly using a simulator—and then passing real-world flight tests with high marks.
One of the biggest limitations in table pre-training has been data collection. Unlike free-form text, which is abundant online, useful tabular data is scarce, diverse, and hard to align with meaningful queries. TAPEX solves this by generating artificial tables and questions, then pairing them with known answers derived through execution—hence the “execution” in its name.

The process starts by creating synthetic tables using defined schema templates. These tables aren't scraped from existing sources; they're generated with rules and logic that ensure varied column types, such as names, numbers, or dates. TAPEX then constructs corresponding questions that can be answered by executing logical operations on these tables—such as sorting, filtering, aggregating, and more. Each question has a traceable answer because the data and logic are controlled.
This method trains the model to recognize patterns in table structure, column relationships, and data interpretation. The absence of real data is actually a strength—it avoids privacy issues, bias from domain-specific content, and dependency on high-quality labelled examples.
By training on millions of synthetic question-answer-table triplets, TAPEX allows models to become fluent in table operations without ever needing real-world examples. This synthetic-first approach is efficient, scalable, and surprisingly effective.
While synthetic data might raise concerns about realism or generalizability, TAPEX shows strong performance across real-world benchmarks. After being pre-trained synthetically, TAPEX is fine-tuned on task-specific datasets, such as WikiSQL (for SQL-style queries), TabFact (for fact verification), and SQA (for conversational table QA). The results are competitive with models that are trained directly on human-labeled data.
On WikiSQL, TAPEX achieves state-of-the-art accuracy with much less fine-tuning effort. Its performance demonstrates that the model doesn’t just memorize templates—it learns to generalize over logical reasoning tasks. This indicates a deeper understanding of table semantics, not just surface-level matching.
Another strength of TAPEX is its interpretability. Since it is trained to perform execution-based tasks, its predictions often follow clear, logical steps that align with the query's intention. This makes TAPEX models easier to analyze and debug, which is helpful in real-world applications where transparency matters.
Moreover, TAPEX’s training method is modular. Developers can easily create new synthetic datasets tailored to specific domains (e.g., finance, sports, health) by tweaking schema templates and operation rules. This flexibility is rare in traditional models that require large, curated datasets for each domain shift.
The success of TAPEX suggests a strong case for revisiting how we approach data scarcity in machine learning. Instead of gathering more real-world examples, we can ask whether better synthetic environments might be enough to teach models complex behaviours.
TAPEX isn't just another model tweak. It signals a new way to develop systems that understand structured information more than people do. Tables are common—from spreadsheets and dashboards to CSV files and other data platforms. The ability to query, summarize, and interpret them using natural language has long been a challenge for AI.

The use of synthetic data points to a wider shift. As generative AI expands, so does the option to build synthetic training environments that are more targeted and safer. Instead of large-scale data scraping or annotation, TAPEX shows that well-designed artificial data can do much of the work.
For developers, this approach brings practical benefits. TAPEX-trained models can help with automated reporting, interactive dashboards, customer support involving structured records, and education platforms. Since no real data is needed during training, there’s less friction in deployment.
On the research side, TAPEX encourages deeper work into execution-based learning and abstract reasoning. Its method bridges symbolic logic with neural networks—two areas often treated separately. By teaching models to think in steps, TAPEX builds systems that are not just language-aware but logic-aware, too.
TAPEX shows that we don't always need real-world data to build real-world solutions. By generating its synthetic training ground, it proves that a well-designed simulation can teach models how to understand and reason with tables. The benefits are clear: lower data costs, more control, and strong performance across various tasks. As more AI applications involve structured information, approaches like TAPEX may shape the future of how machines learn and reason—efficiently, logically, and without being chained to messy, limited datasets.
Advertisement

Looking for the next big thing in Python development? Explore upcoming libraries like PyScript, TensorFlow Quantum, FastAPI 2.0, and more that will redefine how you build and deploy systems in 2025
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed

The White House has introduced new guidelines to regulate chip licensing and AI systems, aiming to balance innovation with security and transparency in these critical technologies

How BERT, a state of the art NLP model developed by Google, changed language understanding by using deep context and bidirectional learning to improve natural language tasks

Explore how ACID and BASE models shape database reliability, consistency, and scalability. Learn when to prioritize structure versus flexibility in your data systems

Prepare for your Snowflake interview with key questions and expert answers covering Snowflake architecture, virtual warehouses, time travel, micro-partitions, concurrency, and more

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability
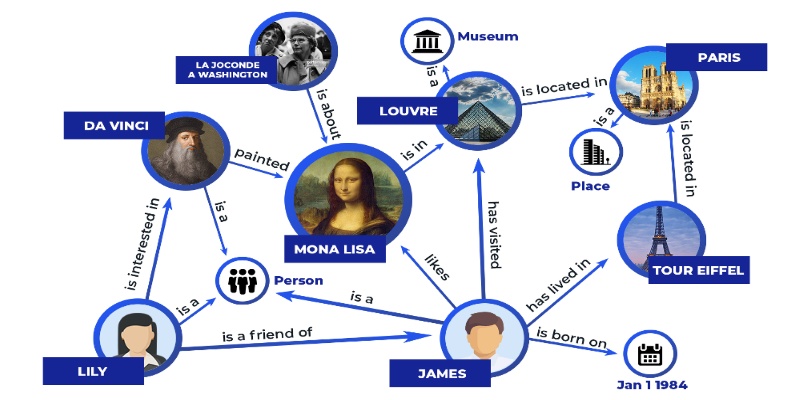
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery

Curious how to build your first serverless function? Follow this hands-on AWS Lambda tutorial to create, test, and deploy a Python Lambda—from setup to CloudWatch monitoring
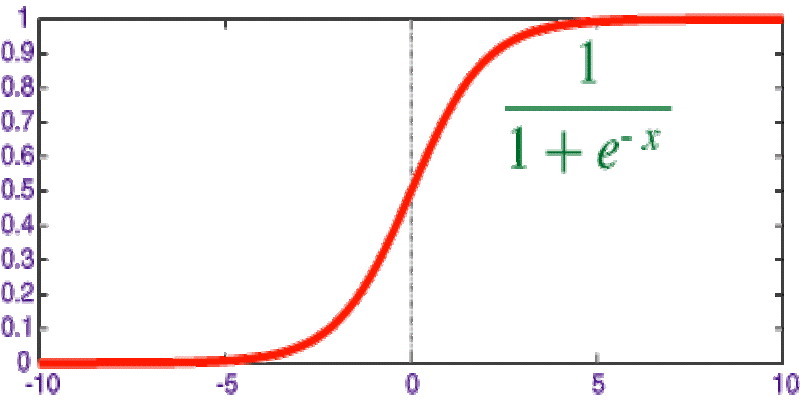
Explore the sigmoid function, how it works in neural networks, why its derivative matters, and its continued relevance in machine learning models, especially for binary classification

Learn how to create a Telegram bot using Python with this clear, step-by-step guide. From getting your token to writing commands and deploying your bot, it's all here

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features