Advertisement
When you're working with time-series data, missing dates can be more than just a minor glitch. They can throw off your entire analysis, mess with rolling calculations, and leave you wondering why your chart suddenly has awkward gaps. And while missing values are a popular topic, missing dates don’t always get the attention they deserve. But don’t worry—fixing this is not as complicated as it might sound. Let’s break it all down so that next time you run into missing dates, you won’t flinch. In fact, you might even feel a little smug.
Before you do anything, it's important to understand how your time-based data is structured. Is your date column an index? Is it a daily, hourly, or weekly frequency? You can't repair what you haven't examined.
Here’s a quick peek at how to inspect and convert your date column properly:
python
CopyEdit
import pandas as pd
# Load your data
df = pd.read_csv('your_file.csv')
# Make sure the 'date' column is in datetime format
df['date'] = pd.to_datetime(df['date'])
# Set it as the index
df.set_index('date', inplace=True)
# Sort it if needed
df.sort_index(inplace=True)
Setting the date as an index is important. Many of the imputation schemes are based on that format, particularly when creating a full date range afterwards. Omitting this step could lead to nonsensical errors at first glance.
Once you’ve got your data’s structure sorted out, the next move is to figure out what your date range should be. This is where you define what’s missing.
Let’s assume your data should have one row per day. You’ll want to create a continuous range that stretches from the earliest to the latest date in your dataset:
python
CopyEdit
# Generate the full date range
full_range = pd.date_range(start=df.index.min(), end=df.index.max(), freq='D')
This will include all days, even weekends or holidays, unless you specify otherwise. If your data skips weekends (like financial data often does), that's something you’ll want to adjust, but for now, this gives you the foundation to work from.
Now that you’ve got your full date range, it's time to bring your DataFrame in line with it. Reindexing is the cleanest way to add in those missing dates without messing up the rest of your data.
python
CopyEdit
# Reindex to fill missing dates
df = df.reindex(full_range)
Once you do this, you'll see that any missing dates are now included, but their associated values will show up as NaN. This is exactly what you want. It means the structure is there, and now it’s just a matter of choosing how to fill in those gaps.
This part depends on the nature of your data. Are you working with sales figures, temperature readings, stock prices, or something else? Different kinds of data call for different fill strategies.

Here are three commonly used options:
Great for when values don’t change rapidly, or you’re okay assuming some consistency.
python
CopyEdit
df.fillna(method='ffill', inplace=True)
Use this if it makes more sense to pull in the future value instead of the past.
python
CopyEdit
df.fillna(method='bfill', inplace=True)
Sometimes you just want to fill in zeros or a specific placeholder.
python
CopyEdit
df.fillna(0, inplace=True)
Of course, you don’t have to use just one method across the board. If you’re working with multiple columns, you can apply different strategies per column. That gives you more control without overcomplicating things.
It’s easy to assume that if your DataFrame looks fine at a glance, everything’s in place. But that’s often not the case with dates—they can disappear silently. To catch them early, it helps to do a quick check before moving on to deeper analysis.
Start by looking at the difference between dates:
python
CopyEdit
# Check date gaps
date_diff = df.index.to_series().diff()
print(date_diff.value_counts())
This gives you a list of how many times each time gap appears. If you're expecting one day between each entry and suddenly see two or more, you know something’s missing.
You can also use a simple visual check by plotting the data points against time. Sharp drops in frequency or obvious gaps in the timeline are red flags. These small steps can save you from having to debug more complex issues later on.
And if you're working with large datasets where missing dates aren't easy to spot manually, automating the check with assertions can be a smart move:
python
CopyEdit
# Assert consistent daily frequency
expected_range = pd.date_range(start=df.index.min(), end=df.index.max(), freq='D')
assert df.index.equals(expected_range), "Missing dates detected!"
Catching problems early is always better than retrofitting fixes after the fact. So while it might feel like an extra step, verifying your dates upfront can help you avoid trouble down the line.
Missing dates in time-based data can cause more problems than they first appear to be. Whether it's gaps in charts or skewed calculations, overlooking them often leads to misleading results. Fortunately, fixing them isn't complex once you understand the structure your data should follow and apply a few consistent steps in Python.
The key is to first convert and sort your date column properly, then generate a complete date range that reflects what should be there. Reindexing your DataFrame against this full range allows the missing dates to surface clearly. From there, it's about selecting the right fill method—forward, backward, or fixed—based on the nature of your data.
Advertisement

How are conversational chatbots in the Omniverse helping small businesses stay competitive? Learn how AI tools are shaping customer service, marketing, and operations without breaking the budget

How accelerated inference using Optimum and Transformers pipelines can significantly improve model speed and efficiency across AI tasks. Learn how to streamline deployment with real-world gains

How explainable artificial intelligence helps AI and ML engineers build transparent and trustworthy models. Discover practical techniques and challenges of XAI for engineers in real-world applications

Explore Proximal Policy Optimization, a widely-used reinforcement learning algorithm known for its stable performance and simplicity in complex environments like robotics and gaming
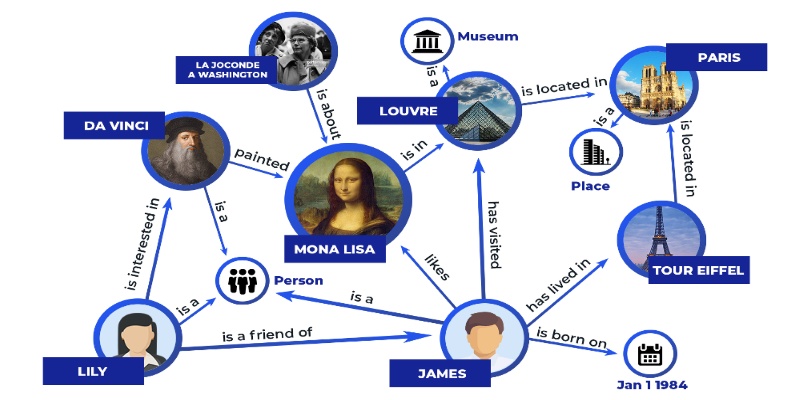
Discover how knowledge graphs work, why companies like Google and Amazon use them, and how they turn raw data into connected, intelligent systems that power search, recommendations, and discovery
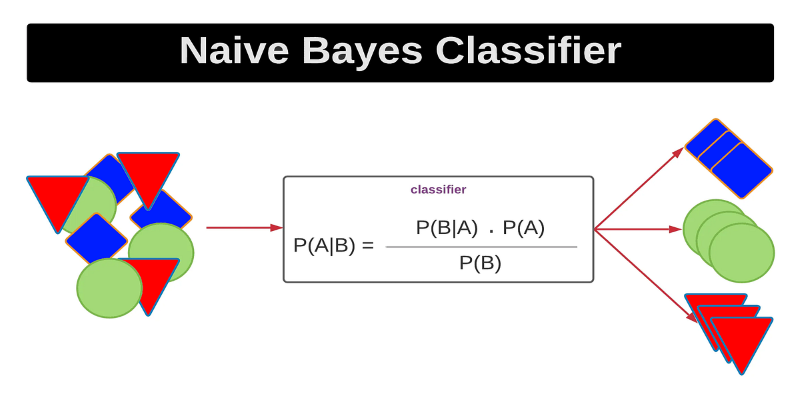
Curious how a simple algorithm can deliver strong ML results with minimal tuning? This beginner’s guide breaks down Naive Bayes—its logic, types, code examples, and where it really shines
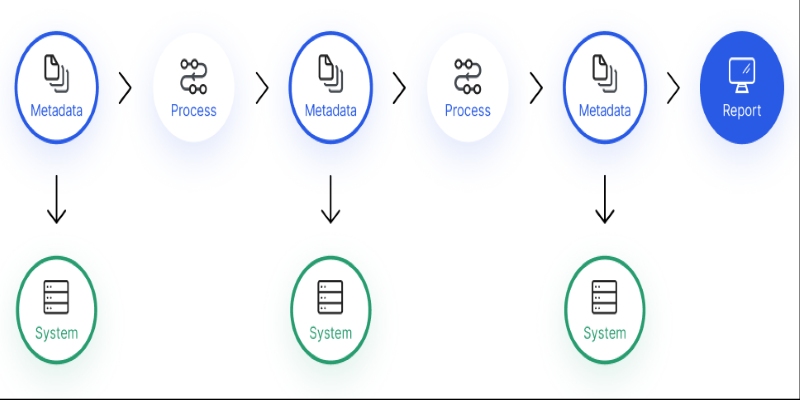
Confused about where your data comes from? Discover how data lineage tracks every step of your data’s journey—from origin to dashboard—so teams can troubleshoot fast and build trust in every number

Confused about DAO and DTO in Python? Learn how these simple patterns can clean up your code, reduce duplication, and improve long-term maintainability

Gradio is joining Hugging Face in a move that simplifies machine learning interfaces and model sharing. Discover how this partnership makes AI tools more accessible for developers, educators, and users

Prepare for your Snowflake interview with key questions and expert answers covering Snowflake architecture, virtual warehouses, time travel, micro-partitions, concurrency, and more
Learn how Redis OM for Python transforms Redis into a model-driven, queryable data layer with real-time performance. Define, store, and query structured data easily—no raw commands needed

Discover how Google BigQuery revolutionizes data analytics with its serverless architecture, fast performance, and versatile features